

当前生成式AI正处于规模化落地的关键阶段,大语言模型在线推理的服务质量已经成为C端AI应用、B端AI服务的核心竞争壁垒,其中首token延迟作为用户发起请求后收到第一帧回复的时间差,直接决定用户体验的第一感知,也是云服务商、AI芯片企业、模型部署方共同关注的核心性能指标。随着数据要素市场化建设的持续推进,高质量AI训练数据的确权、流通已经成为产业刚需,浙江省数据知识产权登记平台作为国内省级层面率先落地的规范化数据知识产权登记载体,承担着数据资产存证、权益确认、流通支撑等核心职能,为合规的数据要素交易提供公信力背书,有效保障数据供给方的合法权益。
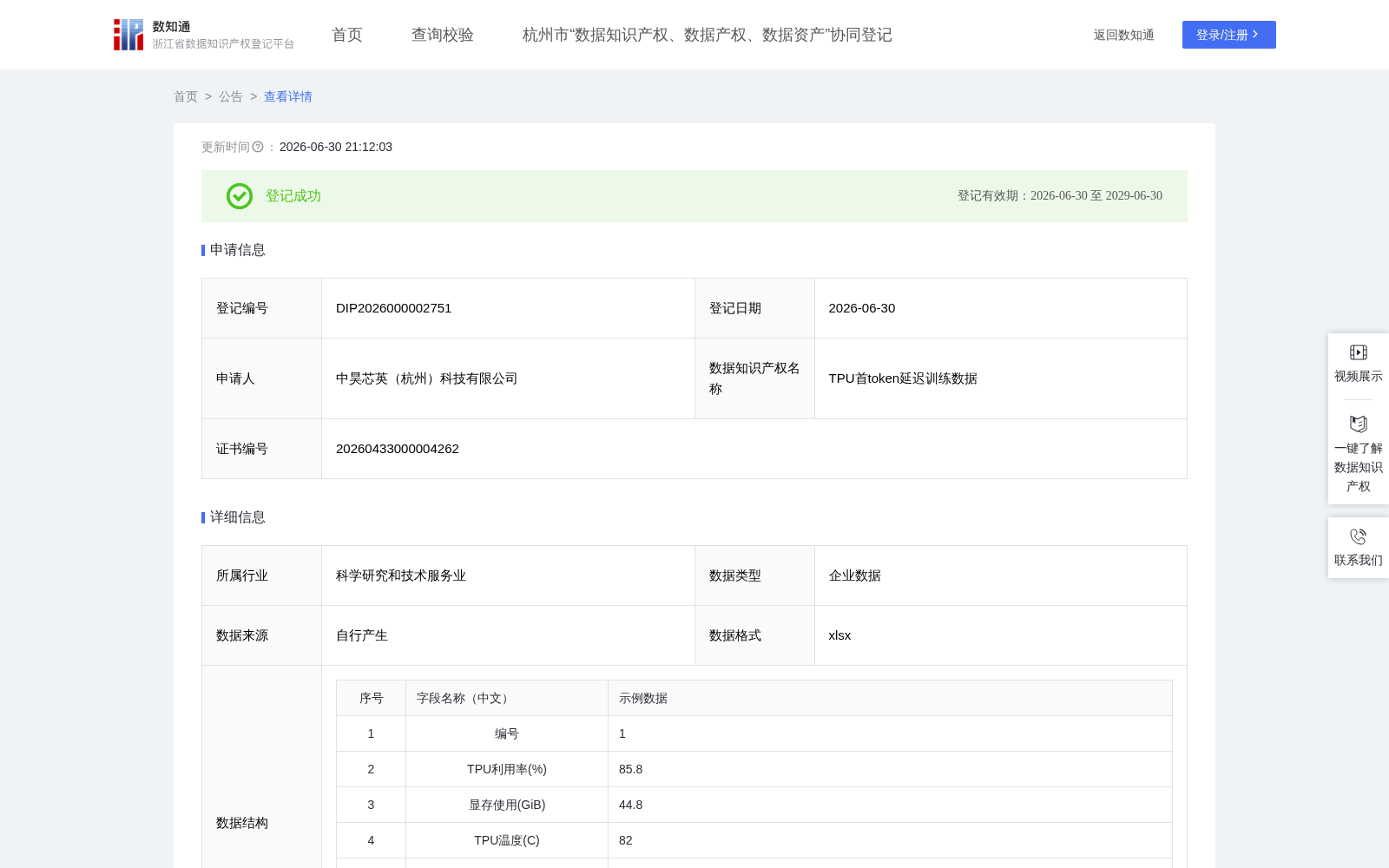
2026年6月30日,中昊芯英(杭州)科技有限公司旗下的TPU首token延迟训练数据正式在该平台完成知识产权登记,该数据集专门针对TPU运行大语言模型在线推理场景的性能预测需求构建,可用于训练回归模型,基于TPU实时运行的六大核心状态参数实现首token延迟的精准预判,目前已明确可应用于大模型推理性能预测、AI硬件资源调度等多个核心领域。
不同于通用训练数据,本次登记的数据集全部来自真实TPU推理环境,覆盖完整工况范围,其加工流程与数据质量均经过严格验证:
一、原始数据基础
加工前的原始数据为TPU运行大语言模型在线推理服务的状态监控日志,每行对应一个请求时刻,字段包括编号、TPU利用率(%)、显存使用(GiB)、TPU温度(℃)、TPU功率(W)、请求排队长度、显存带宽利用率(%)、首token延迟(ms)。所有字段均为数值型且无缺失值,数据总量达数千行以上,覆盖不同负载强度、排队长度及热状态,具备极强的场景代表性。
二、标准化处理规则
为保障数据的可用性与一致性,研发团队对原始数据进行了全流程标准化处理:首先完成数据清洗,剔除超出物理合理范围的记录(如负值、超过硬件极限的值),删除所有字段完全相同的重复记录;随后完成特征与目标定义,明确自变量为TPU利用率、显存使用、TPU温度、TPU功率、请求排队长度、显存带宽利用率共6项核心参数,因变量为首token延迟;其次对全部自变量进行Z-score标准化,消除量纲影响,标准化参数(均值、标准差)由训练集计算,并应用于验证集和测试集;再将清洗后的完整数据按8:1:1的比例随机划分为训练集、验证集和测试集,保证三部分数据分布一致;最终完成模型验证,基于随机森林回归算法(输入6个自变量,输出首token延迟),通过网格搜索优化超参数(树数量、最大深度等),特征重要性分析表明,请求排队长度和TPU利用率是影响首token延迟的主要因素,模型在测试集上达到R² > 0.86,训练集与测试集误差差异小于6%,无过拟合迹象,充分证明了数据集的有效性。
三、最终数据集内容
最终产出数据集为表格形式,包含编号、6个自变量、1个因变量,共8个字段,所有记录均来自真实TPU推理环境,覆盖完整工况范围,数据已标准化并按8:1:1划分,可直接用于监督学习回归任务,训练首token延迟预测模型。
该数据集的应用场景覆盖AI算力产业链多个核心环节:对于云服务商而言,可基于该数据集训练的模型实时监控TPU负载与排队情况,提前预测首token延迟是否即将超过服务等级协议(SLA)阈值(如50ms),并据此触发动态扩容、请求限流或优先级调度,避免因响应过慢导致用户流失,同时降低不必要的算力浪费;对于AI芯片厂商而言,可通过数据分析不同负载条件下首token延迟与硬件状态(温度、功率、带宽利用率)的关联,定位性能瓶颈是计算、访存还是热节流,为芯片调度策略优化提供数据支撑,缩短产品迭代周期;对于模型部署工程师而言,可在离线仿真环境中评估排队策略、并发上限对首token延迟的影响,提前优化系统参数,降低线上故障风险。
本次数据知识产权登记既明确了该数据集的权益归属,为后续其市场化流通、授权使用奠定了合规基础,也为AI算力领域高价值训练数据的确权流程提供了可参考的实践样本,进一步丰富了浙江省数据要素市场的供给品类,助力AI产业的规范化、高质量发展。
登记内容:



_1769672084863.jpg)