

Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University 本次发布的数据集 LongReward-10k, LongReward-10k数据集包含10,000个长上下文问答实例,涵盖英语和中文,每个实例最多可达64,000字。数据集分为三个部分:sft、dpo_glm4_9b和dpo_llama3.1_8b。sft部分包含通过GLM-4-0520模型生成的SFT数据,用于监督微调两个模型:LongReward-glm4-9b-SFT和LongReward-llama3.1-8b-SFT。dpo_glm4_9b和dpo_llama3.1_8b部分是长上下文偏好数据集,用于训练DPO模型:LongReward-glm4-9b-DPO和LongReward-llama3.1-8b-DPO。这些模型基于相应的SFT模型和LongReward方法进行训练。
Dataset card 内容:
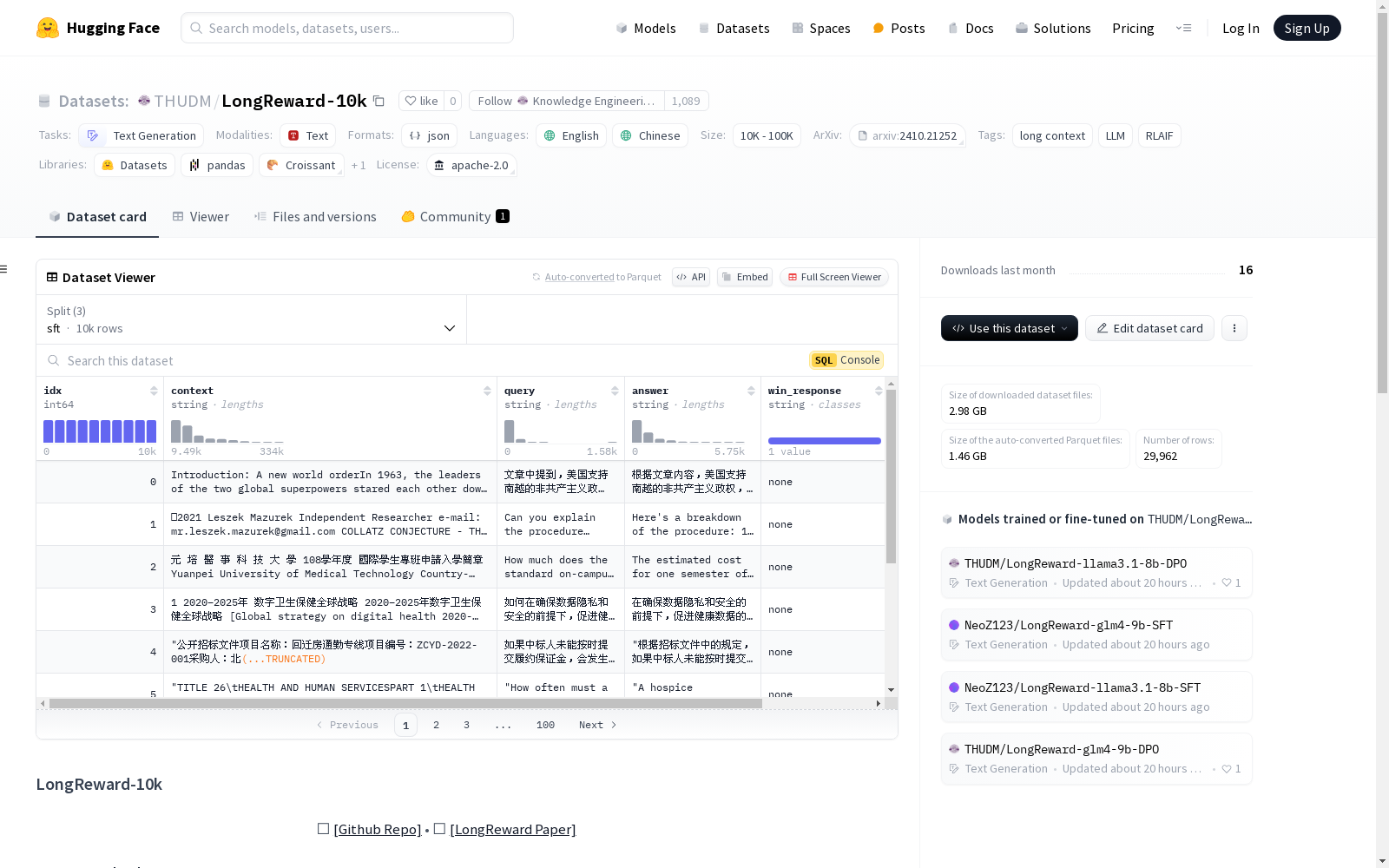
Files and versions 内容:
关于 Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University , 清华大学知识工程研究室(KEG)和数据挖掘小组(THUDM)专注于大型语言模型研究与应用。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)