

广东工业大学 本次发布的数据集 Indonesian GEC Evaluation Corpus, 本数据集由广东工业大学计算机科学与技术学院的研究团队创建,旨在为印度尼西亚语的语法错误纠正(GEC)任务提供高质量的评估语料。数据集包含了从2007年到2021年从Antara News Agency爬取的631,964篇文章,涵盖科技、政治、法律、经济、体育和人文六个主题,共计7,613,950条句子。创建过程中,研究团队首先使用合成数据训练印度尼西亚语GEC模型,然后应用该模型修正真实新闻语料中的错误,并通过人工标注建立黄金标准评估语料。该数据集主要用于低资源语言的GEC任务,旨在解决印度尼西亚语等低资源语言在NLP研究中缺乏高质量评估语料的问题。
查看Indonesian GEC Evaluation Corpus
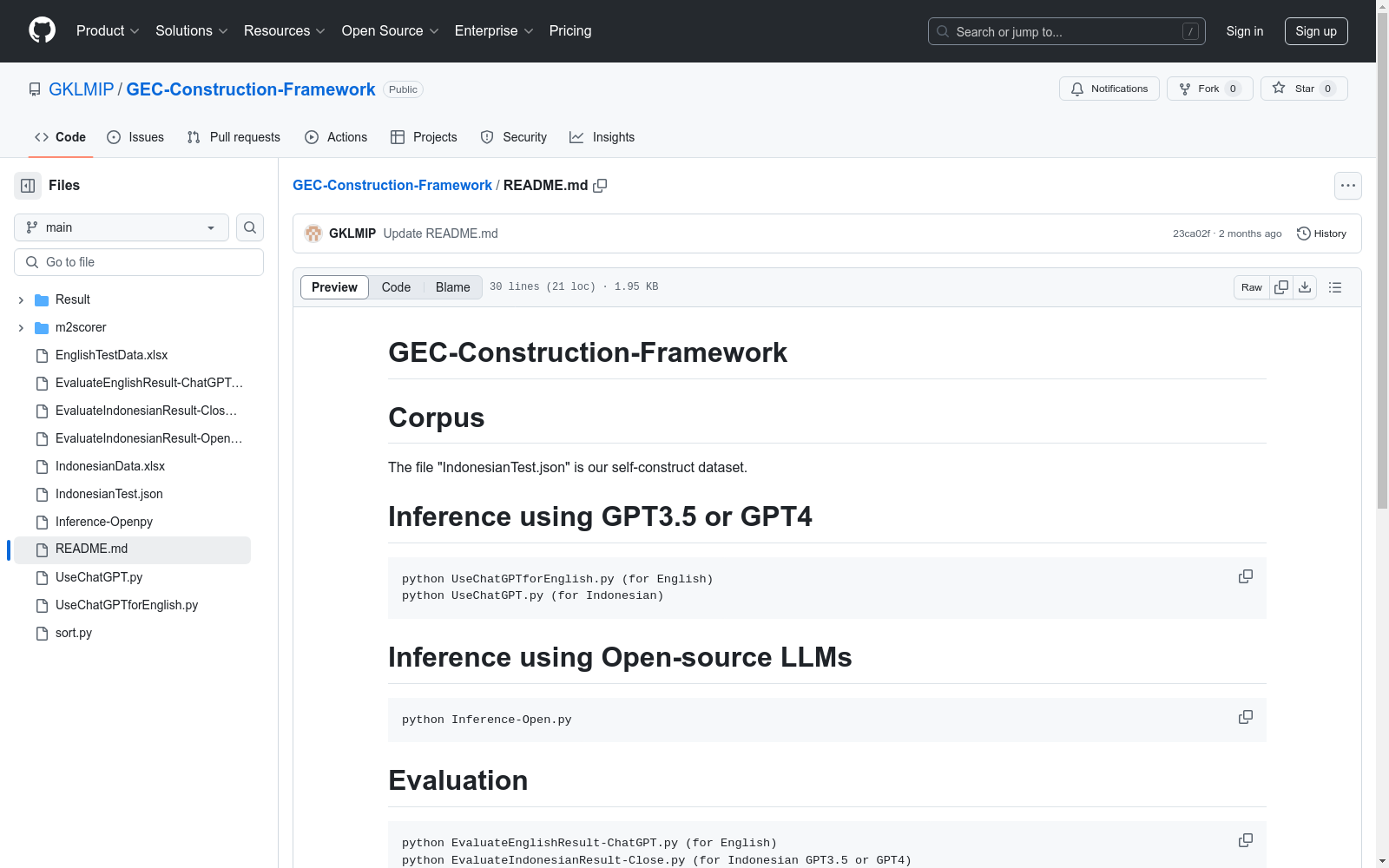
README 内容:
关于 广东工业大学 , 广东工业大学是一所以工为主,工、理、经、管、文、法、艺术等多学科协调发展的省属重点大学,位于中国广东省广州市。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)