

北京人工智能研究院 本次发布的数据集 CCI3.0-HQ, CCI3.0-HQ是由北京人工智能研究院开发的一个大规模高质量中文预训练数据集,旨在提升大型语言模型的训练效果。该数据集包含500GB的高质量文本,涵盖新闻、社交媒体和博客等多种来源,通过两阶段混合过滤策略进行数据清洗和质量提升。数据集的创建过程包括基础处理和高质处理两个阶段,确保了数据的高质量和多样性。CCI3.0-HQ主要应用于中文语言模型的预训练,旨在解决现有中文数据集质量不高和数据量不足的问题,从而提升中文语言模型的性能。
Dataset card 内容:
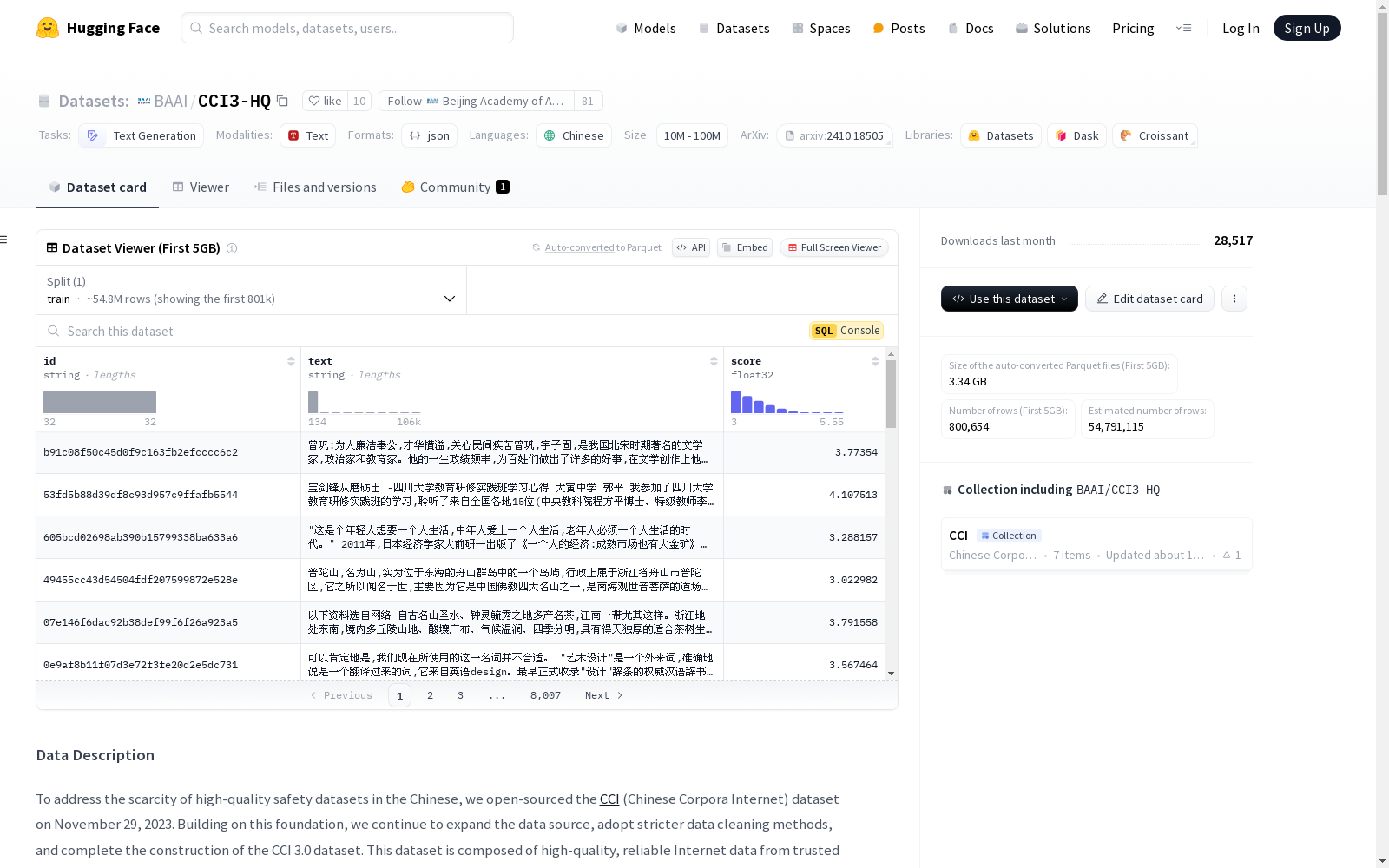
Files and versions 内容:
关于 北京人工智能研究院 , 北京人工智能研究院是一家专注于人工智能技术研究和应用的机构,致力于推动人工智能领域的前沿技术发展。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)