

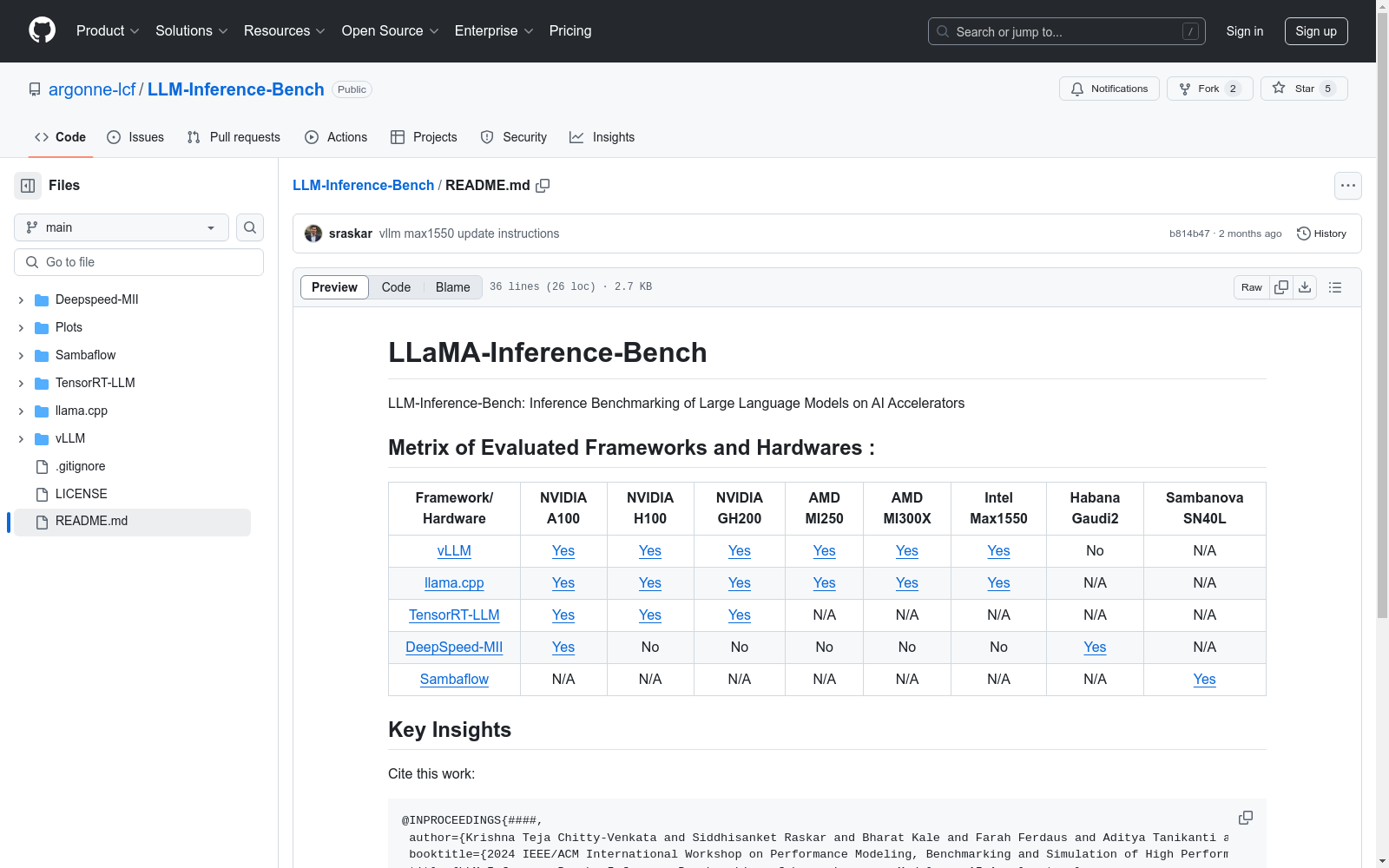
阿贡国家实验室 本次发布的数据集 LLM-Inference-Bench, LLM-Inference-Bench是由阿贡国家实验室创建的一个综合基准测试套件,旨在评估大型语言模型在多种AI加速器上的推理性能。该数据集涵盖了从7亿到70亿参数的多种LLM模型,包括LLaMA、Mistral和Qwen系列,并分析了不同硬件平台(如Nvidia和AMD的GPU以及Intel Habana和SambaNova的AI加速器)上的性能。数据集的创建过程包括对多种推理框架(如vLLM、TensorRT-LLM、llama.cpp和Deepspeed-MII)的全面评估,旨在为研究人员提供优化LLM性能和硬件选择的参考。该数据集主要应用于自然语言处理、内容生成和决策支持系统等领域,旨在解决LLM在不同硬件平台上的性能瓶颈问题。
README 内容:
关于 阿贡国家实验室 , 阿贡国家实验室是美国能源部下属的一个国家实验室,主要从事科学研究和技术开发,涵盖物理学、化学、生物学、环境科学等多个领域。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)