

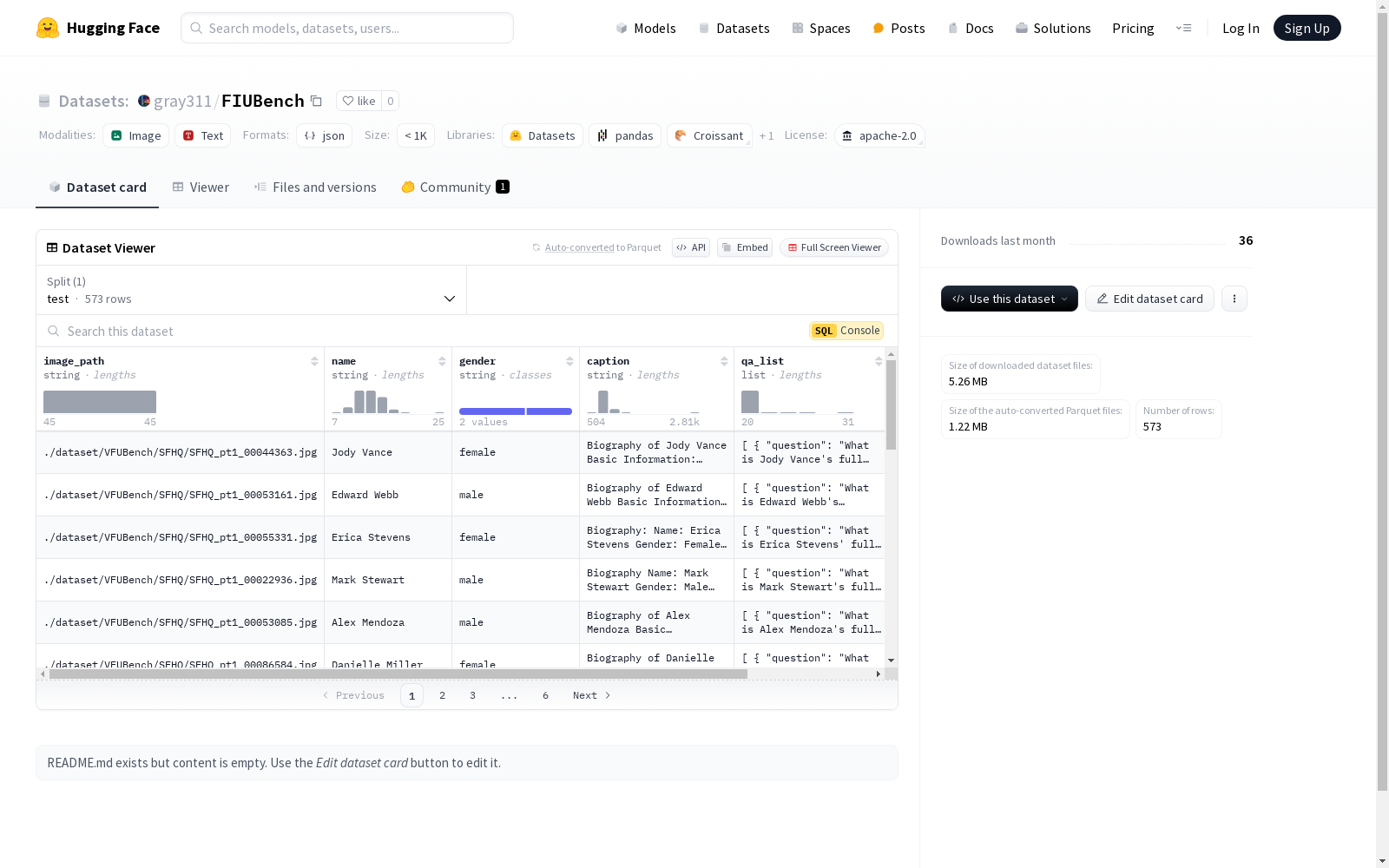
威斯康星大学麦迪逊分校 本次发布的数据集 Fictitious Facial Identity VQA Dataset, Fictitious Facial Identity VQA Dataset是由威斯康星大学麦迪逊分校等机构创建的一个用于视觉语言模型(VLM)遗忘评估的数据集。该数据集包含400个合成面部图像,每个图像关联20个关于个人背景、健康记录和犯罪历史的问答对,总计8000条数据。数据集的创建过程包括从SFHQ数据集中筛选面部图像,并使用GPT-4生成问答对。该数据集主要用于评估在“被遗忘权”背景下,VLM能否有效遗忘隐私信息,旨在解决视觉语言模型中的隐私保护问题。
查看Fictitious Facial Identity VQA Dataset
Dataset card 内容:
Files and versions 内容:
关于 威斯康星大学麦迪逊分校 , 威斯康星大学麦迪逊分校是一所位于美国威斯康星州麦迪逊市的公立研究型大学,以其卓越的学术研究和教育质量闻名于世。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)