

Hugging Face TB Research 本次发布的数据集 smoltalk, SmolTalk 是一个用于大型语言模型(LLM)监督微调(SFT)的合成数据集,包含1百万个样本。该数据集用于构建 SmolLM2-Instruct 系列模型,涵盖多种任务,包括文本编辑、重写、摘要和推理。通过一系列数据消融实验,结合公共数据集,增强了模型在数学、编码、系统提示和长上下文理解等方面的能力。所有新数据集均使用 distilabel 工具生成,并可在 GitHub 上找到生成代码。
Dataset card 内容:
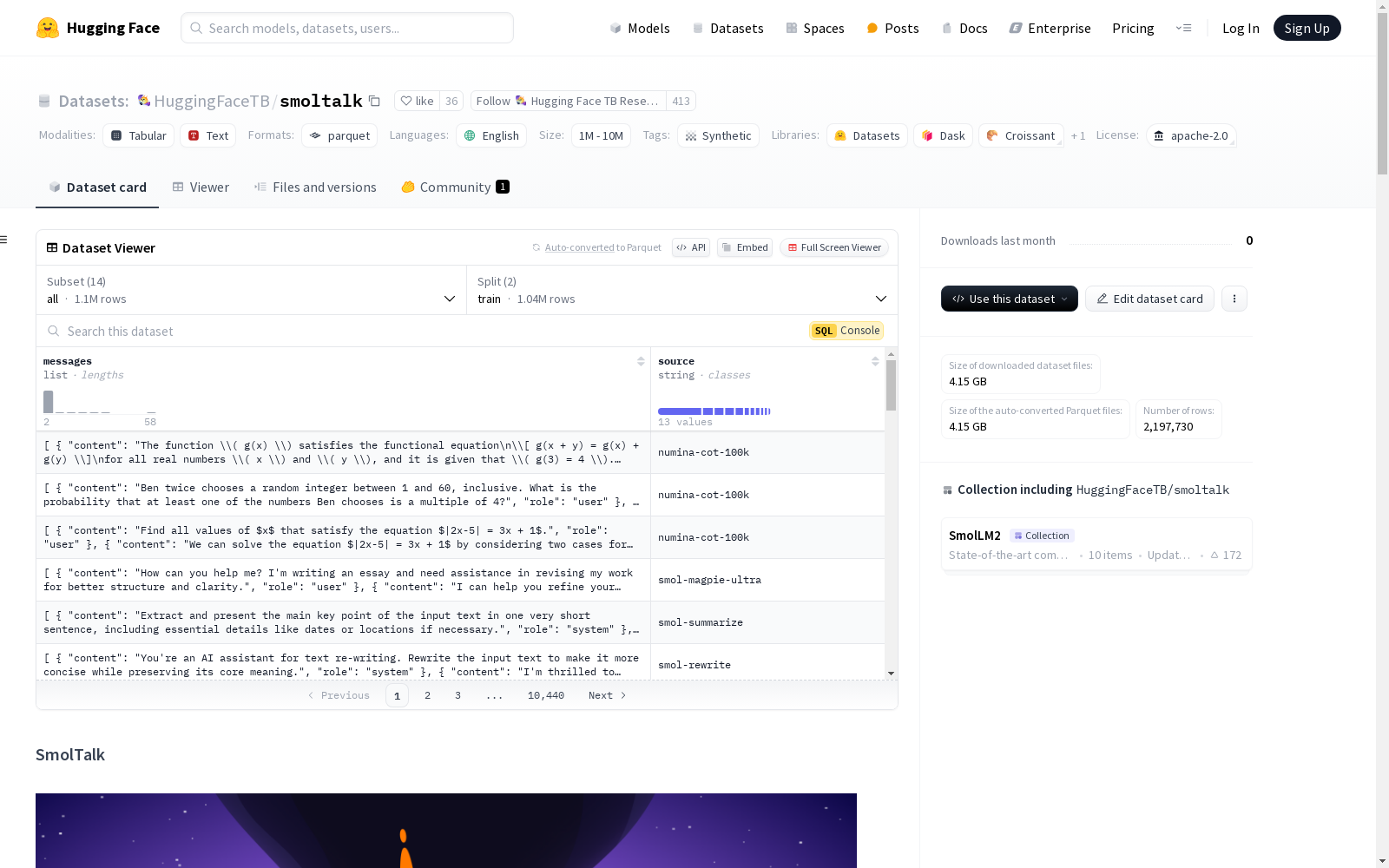
Files and versions 内容:
关于 Hugging Face TB Research , Hugging Face TB Research是Hugging Face旗下专注于大规模语言模型与Transformer技术研究的团队,该机构专注于为预训练提供合成数据集。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)