

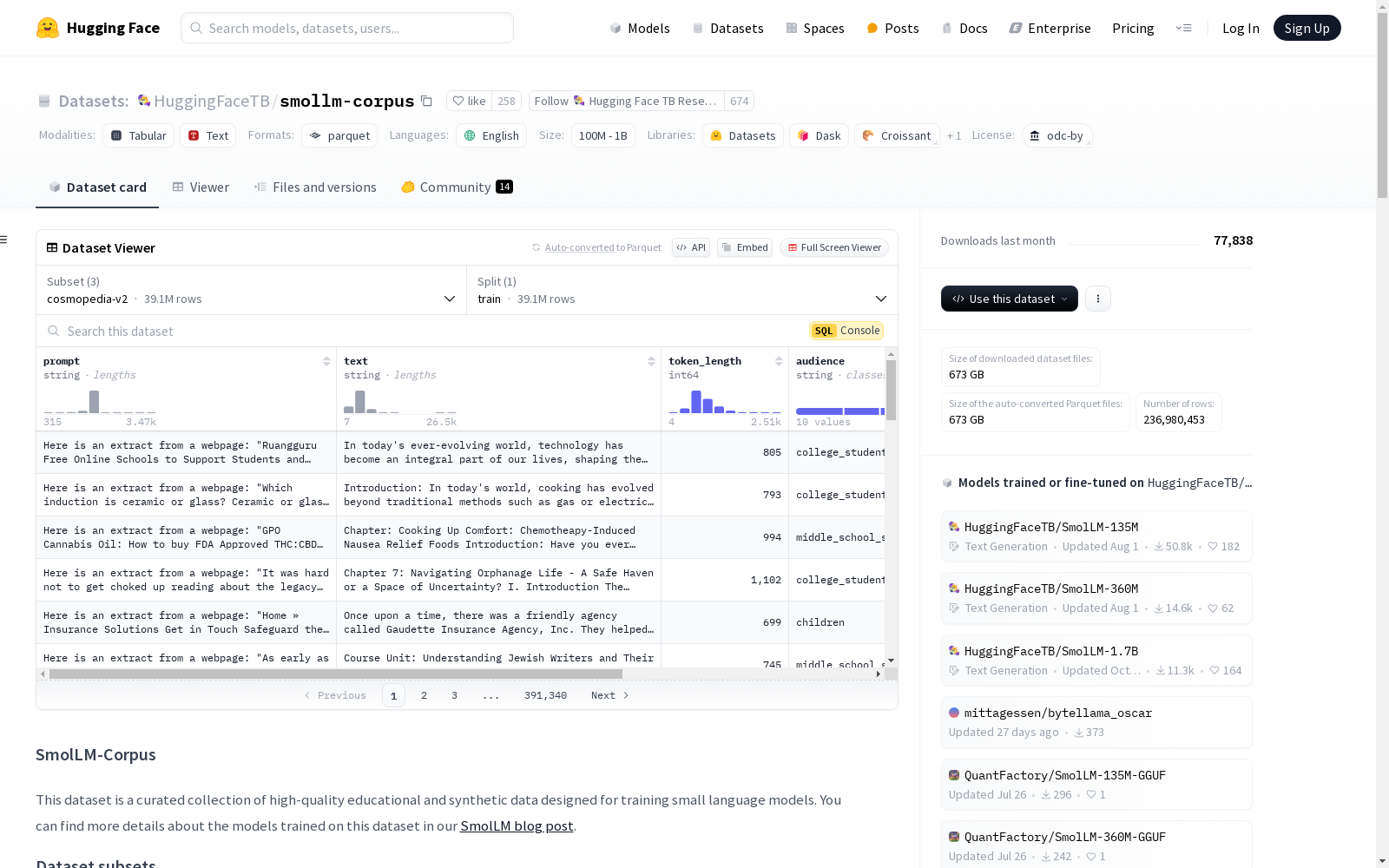
Hugging Face TB Research 本次发布的数据集 smollm-corpus, 该数据集是一个精心策划的高质量教育和合成数据集合,旨在用于训练小型语言模型。数据集包含三个子集:Cosmopedia v2、Python-Edu和FineWeb-Edu (deduplicated)。Cosmopedia v2是一个用于预训练的最大合成数据集,包含超过3900万个由Mixtral-8x7B-Instruct-v0.1生成的教科书、博客文章和故事。Python-Edu子集包含Python文件,这些文件由教育代码模型评分4分以上,并从stack-v2-train数据集中提取。FineWeb-Edu (deduplicated)是FineWeb-Edu数据集的去重子集,包含2200亿个教育网页的标记,使用教育质量分类器过滤,保留最高质量的教育内容。
Dataset card 内容:
Files and versions 内容:
关于 Hugging Face TB Research , Hugging Face TB Research是Hugging Face旗下专注于大规模语言模型与Transformer技术研究的团队,该机构专注于为预训练提供合成数据集。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)