

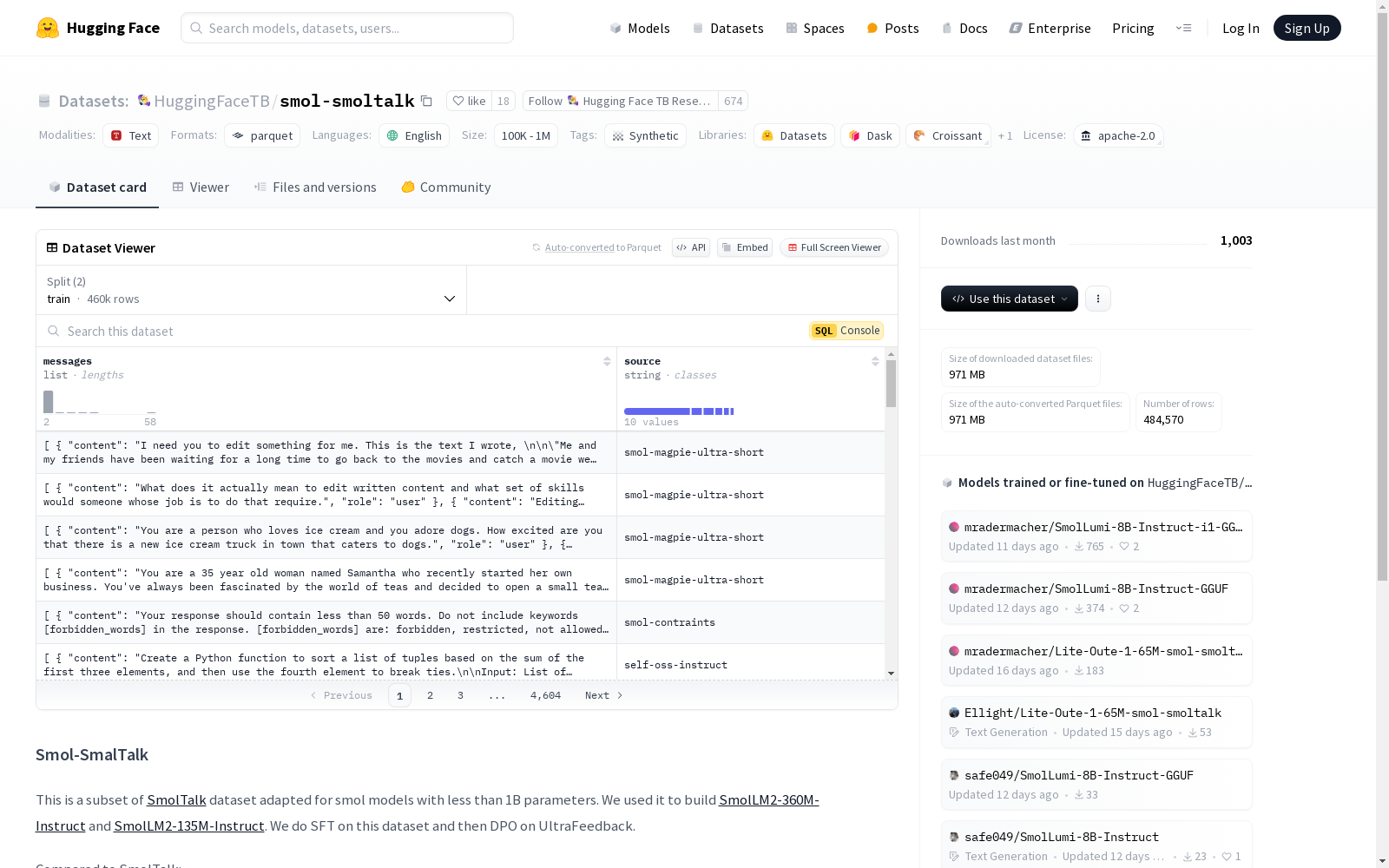
Hugging Face TB Research 本次发布的数据集 smol-smoltalk, Smol-SmolTalk数据集是SmolTalk数据集的一个子集,专门为参数少于1B的小模型设计。该数据集用于构建SmolLM2-360M-Instruct和SmolLM2-135M-Instruct模型。与SmolTalk相比,Smol-SmolTalk的对话更短,包含的任务特定数据更少(如不包含函数调用和较少的重写和总结示例),并且不包含任何高级数学数据集。数据集包含两个主要特征:messages和source。messages是一个列表,包含content和role两个子特征,分别表示消息内容和角色。source表示数据来源。数据集分为训练集和测试集,训练集包含460341个样本,测试集包含24229个样本。
Dataset card 内容:
Files and versions 内容:
关于 Hugging Face TB Research , Hugging Face TB Research是Hugging Face旗下专注于大规模语言模型与Transformer技术研究的团队,该机构专注于为预训练提供合成数据集。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)