

TartuNLP 本次发布的数据集 smugri-mt-bench, SMUGRI-MT-Bench数据集是一个用于评估大型语言模型在多轮对话和指令遵循能力方面的芬诺-乌戈尔语版本。它涵盖了四种极其低资源的芬诺-乌戈尔语言:爱沙尼亚语、利沃尼亚语、科米语和沃罗语。数据集包含80个单轮和多轮问题,分为四个主题:数学、推理、写作和一般。这些问题是从LMSYS-Chat-1M数据集中挑选出来的,并由这些语言的母语者手动翻译成爱沙尼亚语、沃罗语、科米语和利沃尼亚语。此外,数据集还包括每种语言的20个有害提示,以促进在极其低资源场景中识别和解决语言模型的潜在漏洞和偏差的研究。
Dataset card 内容:
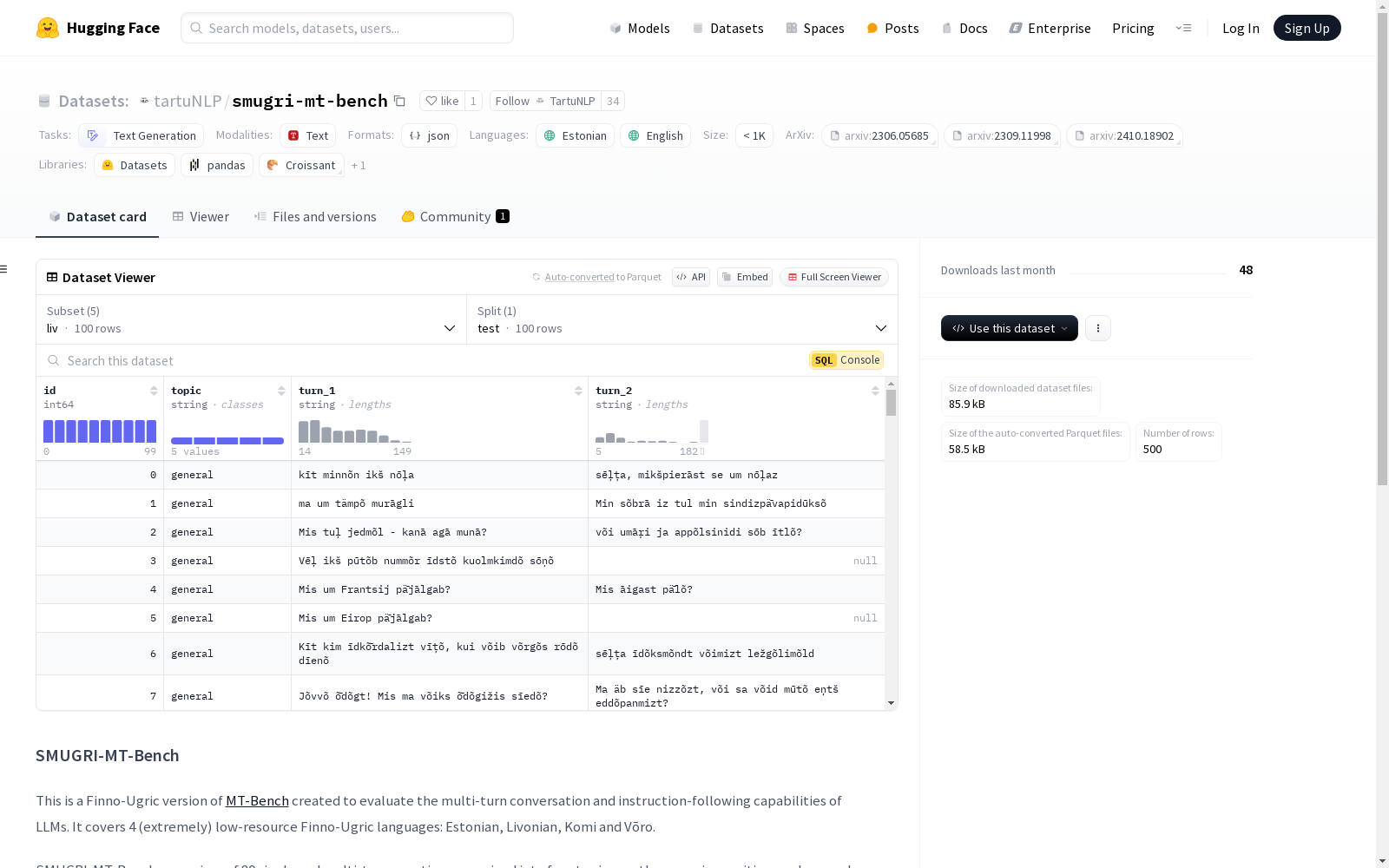
Files and versions 内容:
关于 TartuNLP , TartuNLP是一个专注于自然语言处理领域的研究组织,致力于开发先进的NLP技术和工具,以促进语言技术的创新和应用。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)