

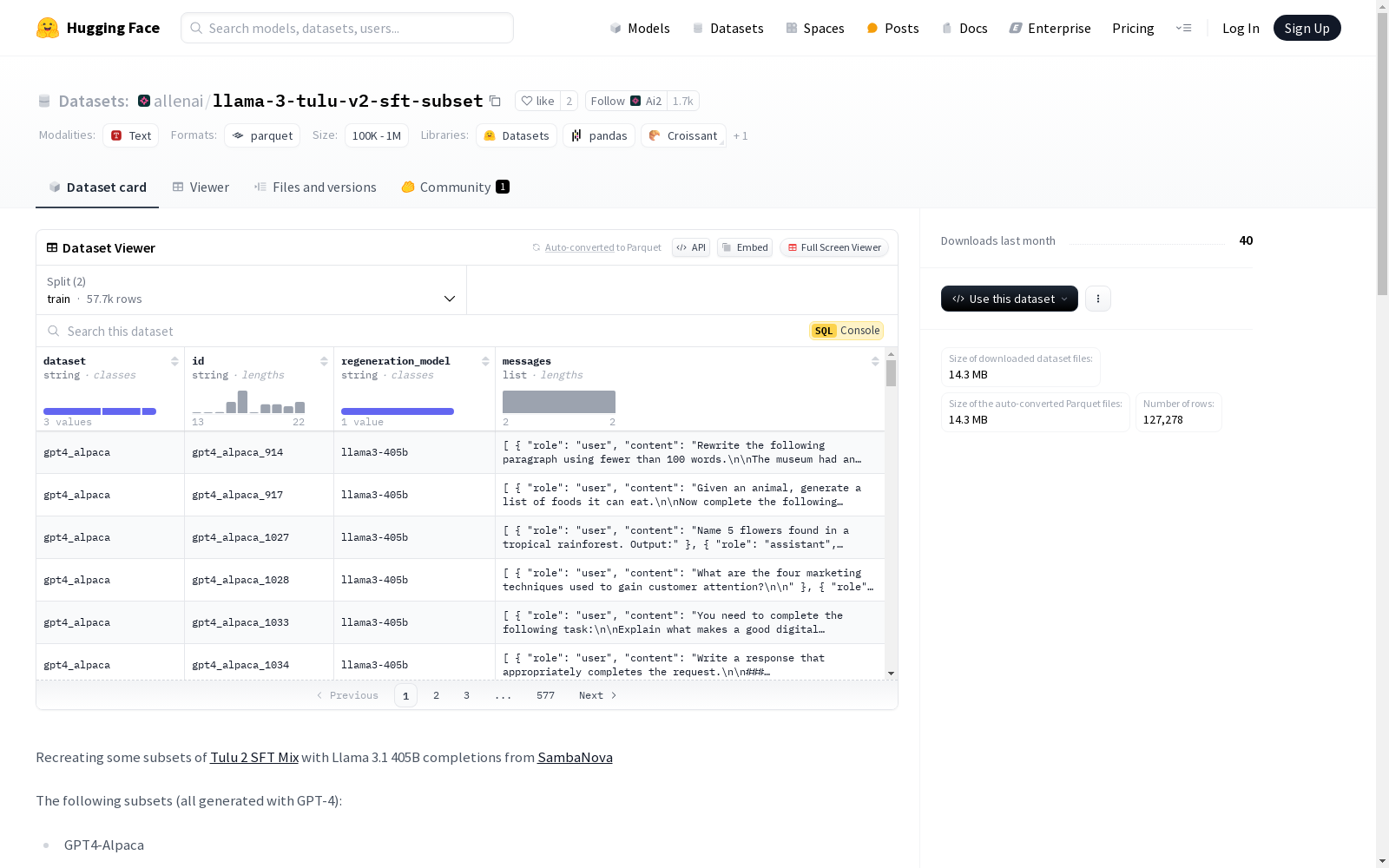
Allen Institute for AI 本次发布的数据集 llama-3-tulu-v2-sft-subset, 该数据集是从[Tulu 2 SFT Mix](https://huggingface.co/datasets/allenai/tulu-v2-sft-mixture)中重新创建的子集,使用Llama 3.1 405B模型生成。数据集包含多个特征,如dataset、id、regeneration_model和messages,其中messages是一个列表,包含role和content两个子特征。数据集分为train和raw两个部分,分别包含57673和69605个样本。子集包括GPT4-Alpaca、Open Orca和Coda Alpaca。原始数据集包含所有Tulu提示,但有些由于API的max_length问题而为空,通过过滤函数去除了这些空内容。
Dataset card 内容:
Files and versions 内容:
关于 Allen Institute for AI , 艾伦人工智能研究所是一家专注于AI研究和应用的高级研究机构。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)