

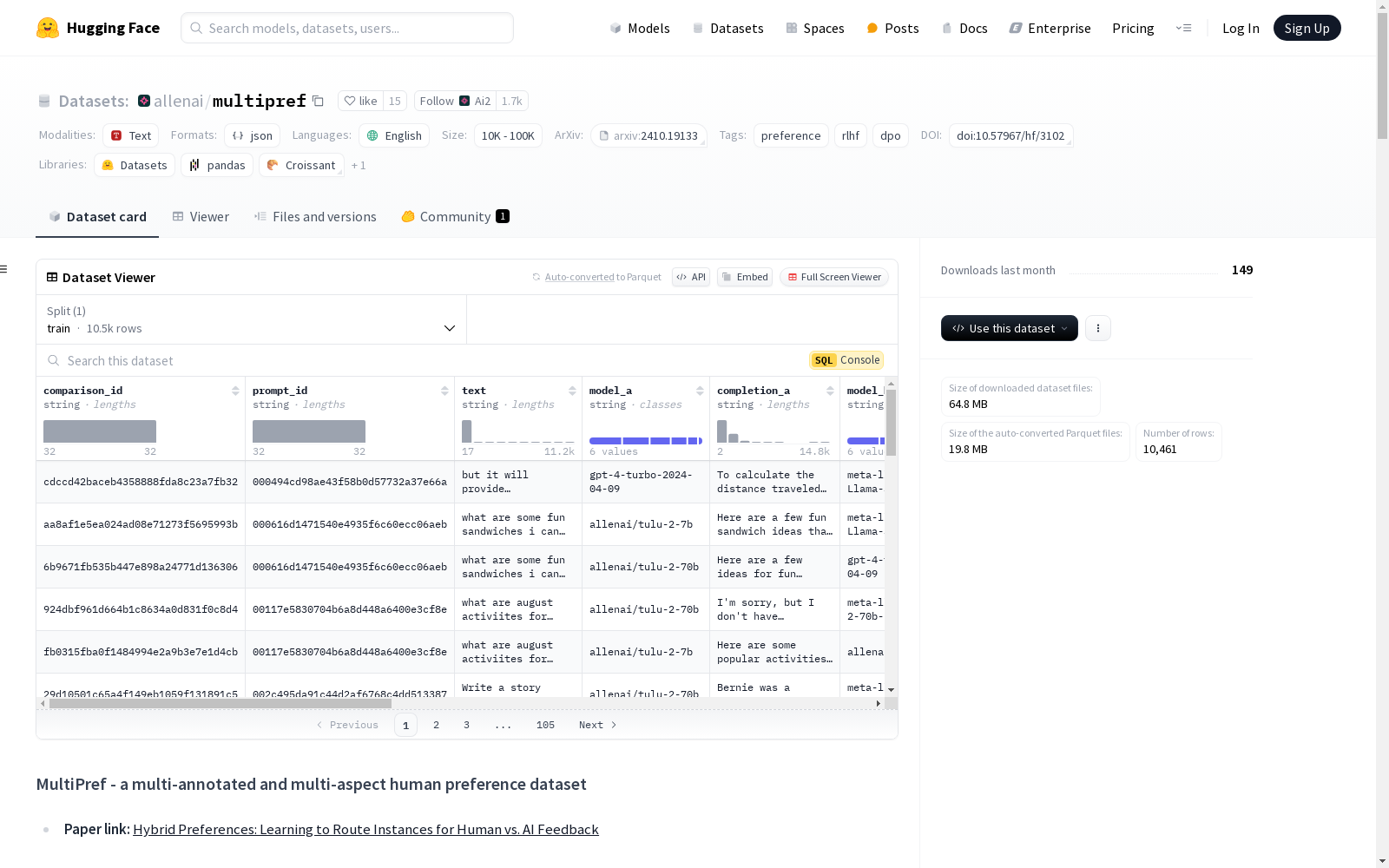
Allen Institute for AI 本次发布的数据集 multipref, MultiPref数据集是一个包含10,000个人类偏好的丰富集合,具有多重注释和多方面的特点。每个实例被普通众包工作者和领域专家分别注释两次,总共有大约40,000个注释。除了整体偏好外,注释者还在五个方面的Likert量表上选择他们偏好的响应,包括帮助性、真实性和无害性。此外,注释者还说明了他们认为一个响应优于另一个的原因。数据集的结构包括每个实例的多个字段,如比较ID、提示ID、文本、模型生成的响应、来源、类别、学科研究、最高学位、普通工作者和专家工作者的注释等。注释字段包括每个方面的偏好、检查原因、自由形式的原因、注释者的信心、整体偏好和信心、评估者ID、注释时间、提交时间戳等。数据集的创建涉及从多个数据源获取提示,并使用多个模型生成响应,然后进行配对比较和随机选择进行注释。注释者包括普通众包工作者和领域专家,他们通过资格测试进行筛选。
Dataset card 内容:
Files and versions 内容:
关于 Allen Institute for AI , 艾伦人工智能研究所是一家专注于AI研究和应用的高级研究机构。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)