

Projecte Aina 本次发布的数据集 ES-OC_Parallel_Corpus, ES-OC平行语料库是一个旨在支持西班牙语和阿拉尼斯语(一种在西班牙瓦尔达兰地区使用的奥克西坦语变体)之间机器翻译任务的数据集。该数据集包含西班牙语和阿拉尼斯语的平行句子,主要通过基于规则的翻译工具Apertium生成,包括从阿拉尼斯语的PILAR单语数据集生成的合成西班牙语,以及通过翻译OPUS中的西班牙语-阿拉尼斯语对生成的合成阿拉尼斯语。数据集以txt和parquet格式提供,每行parquet文件代表一对平行句子。该数据集旨在促进西班牙语和阿拉尼斯语之间的机器翻译发展,并作为WMT24共享任务的一部分,专注于低资源语言的翻译。
Dataset card 内容:
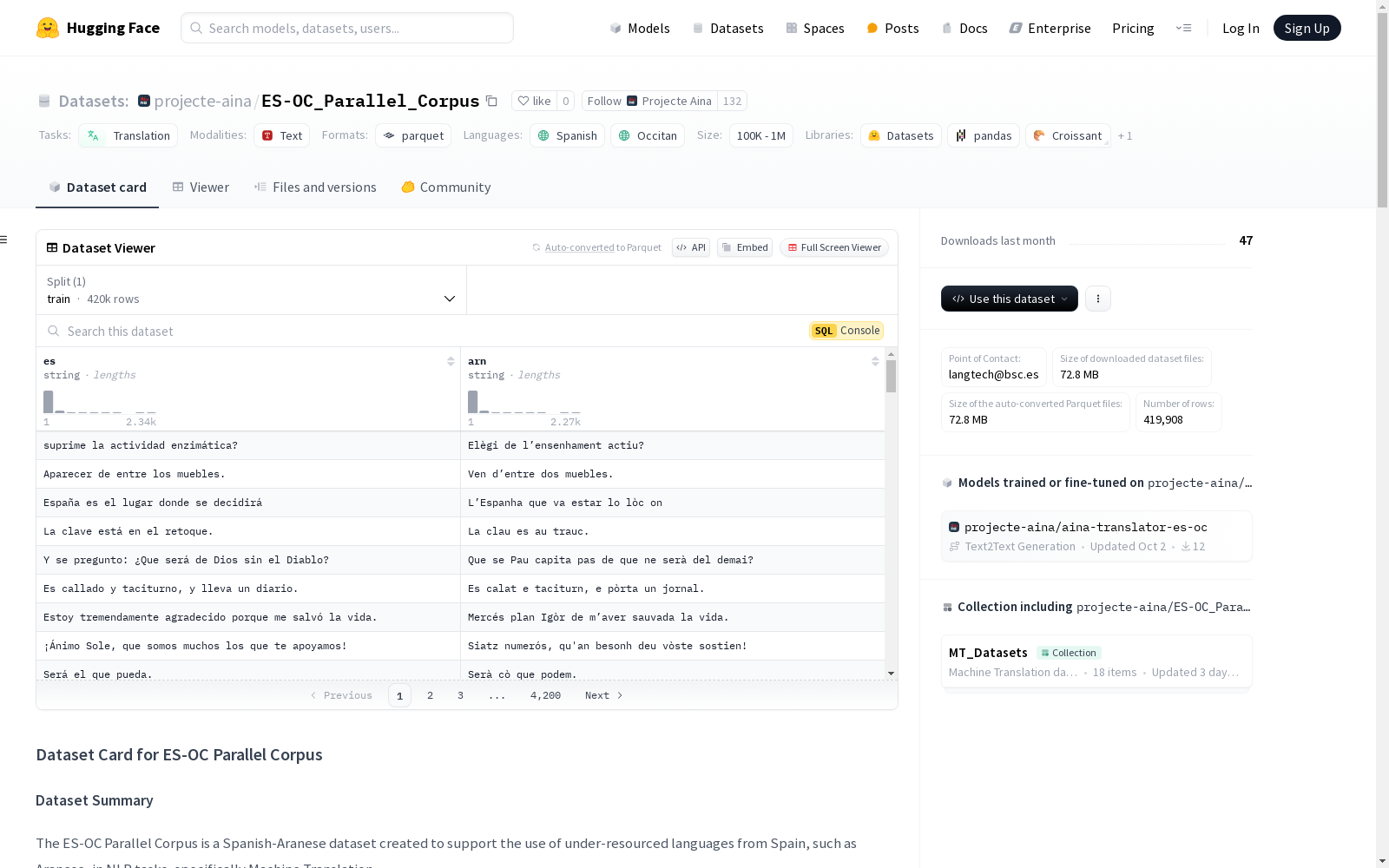
Files and versions 内容:
关于 Projecte Aina , Projecte Aina是一个致力于推动人工智能技术研究和应用的组织。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)