

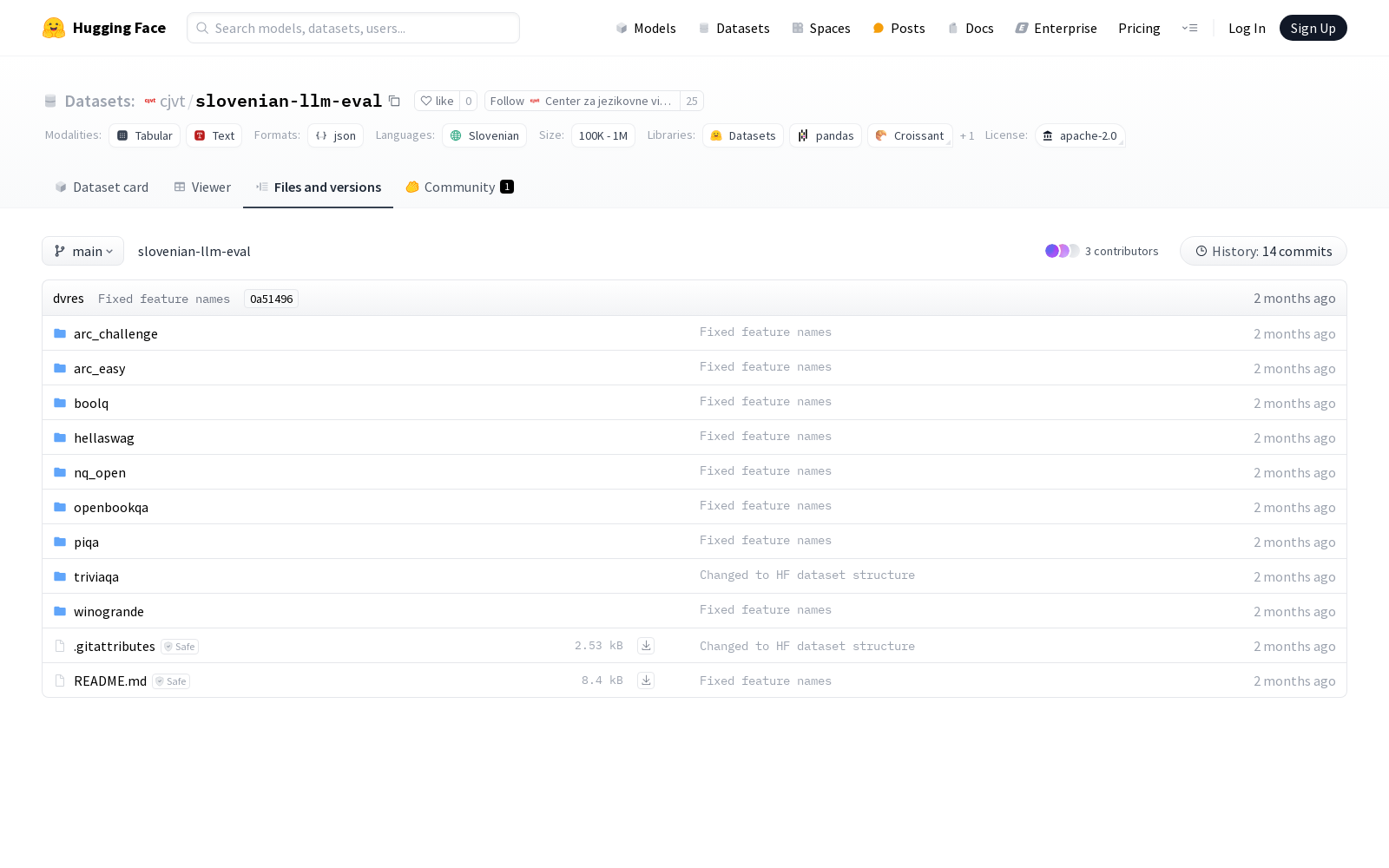
Center za jezikovne vire in tehnologije Univerze v Ljubljani 本次发布的数据集 slovenian-llm-eval, 该数据集是一个用于评估斯洛文尼亚语言模型的数据集,基于gordicaleksa/slovenian-llm-eval-v0的工作,通过Google Translate将一些流行的英语基准翻译成斯洛文尼亚语,并进一步改进了斯洛文尼亚语翻译的质量。数据集包含多个基准测试,如ARC Challenge、ARC Easy、BoolQ、HellaSwag、NQ Open、OpenBookQA、PIQA、TriviaQA和Winogrande。数据集由Tjaša Arčon和Timotej Petrič开发,语言为斯洛文尼亚语,许可证为Apache 2.0。数据集的改进过程使用了Aleksa Gordić的改进流程,并通过OpenAI API进行批量处理。
Dataset card 内容:
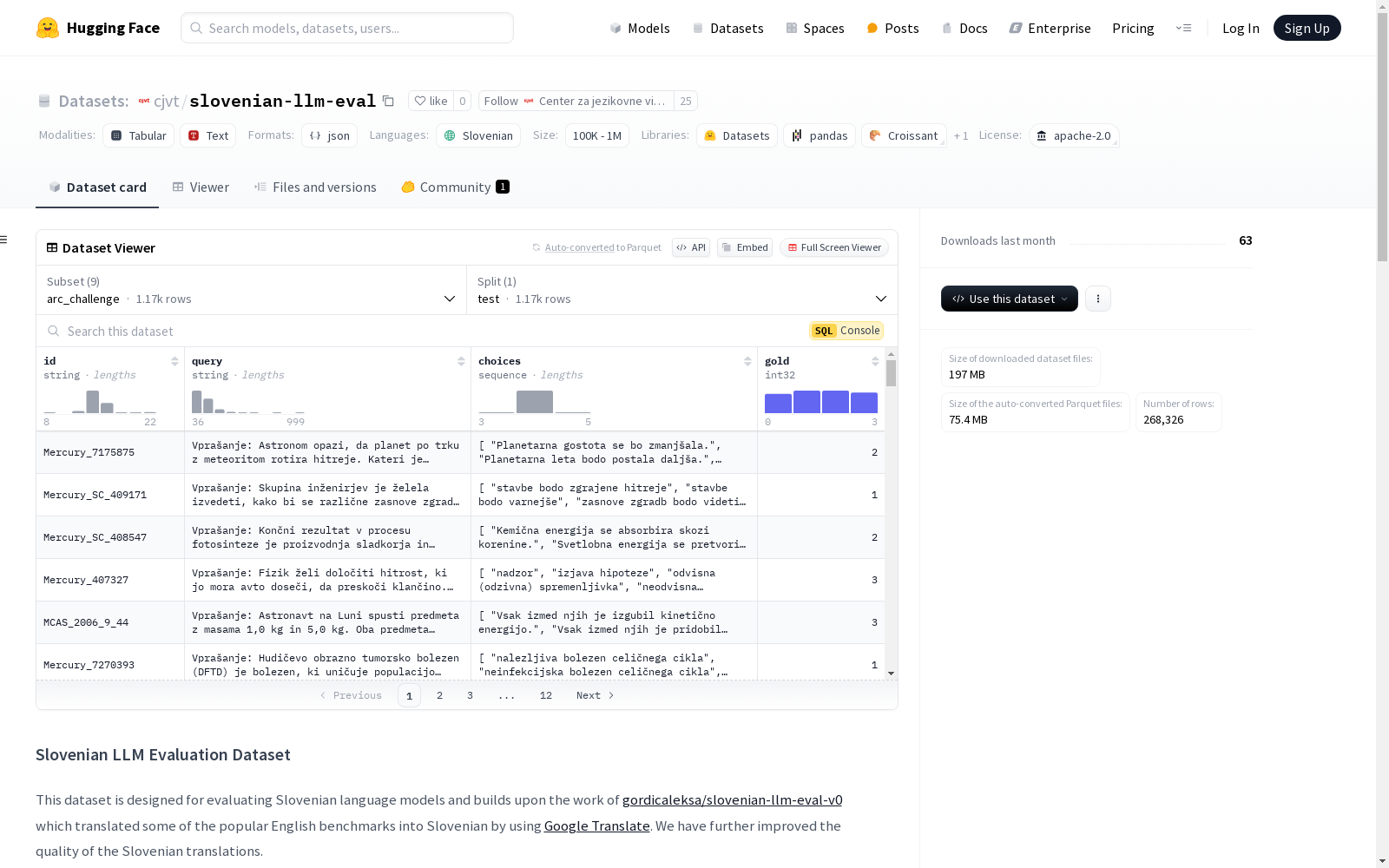
Files and versions 内容:
关于 Center za jezikovne vire in tehnologije Univerze v Ljubljani , Center za jezikovne vire in tehnologije Univerze v Ljubljani是卢布尔雅那大学的一个中心,专注于语言资源和技术的研究与发展。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)