

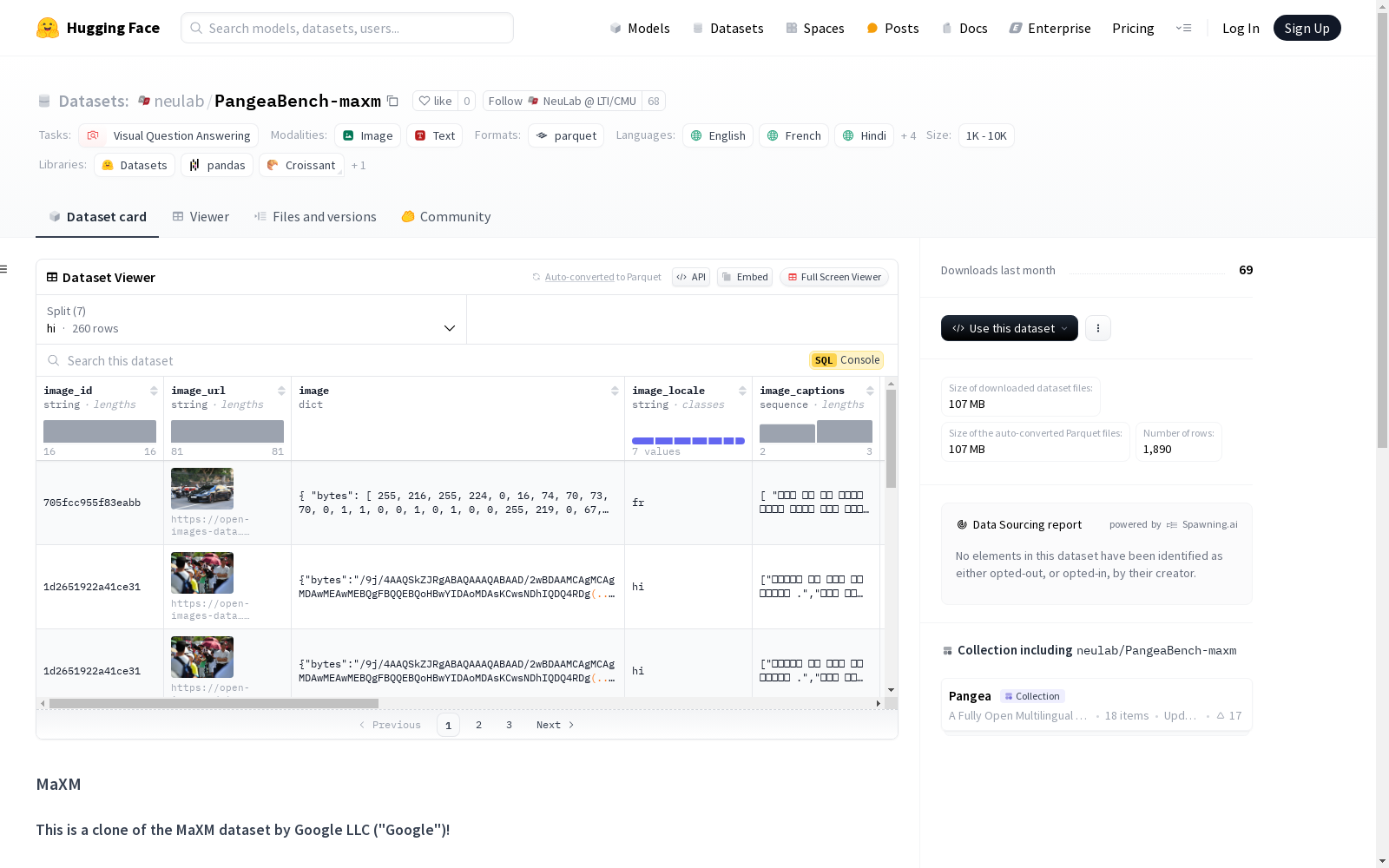
NeuLab @ LTI/CMU 本次发布的数据集 PangeaBench-maxm, MaXM数据集是一个多语言的视觉问答数据集,由Google LLC创建。它包含多种语言的图像、图像描述、问题和答案。数据集的特征包括图像ID、图像URL、图像字节和路径、图像语言、图像描述、问题ID、问题、答案、处理后的答案、语言、是否为集合以及方法。数据集支持的语言包括英语、法语、印地语、罗马尼亚语、泰语、希伯来语和中文。数据集的大小在1K到10K之间,分为多个子集,每个子集对应一种语言。数据集的下载大小为106887693字节,总大小为169766077字节。
Dataset card 内容:
Files and versions 内容:
关于 NeuLab @ LTI/CMU , NeuLab @ LTI/CMU是卡内基梅隆大学语言技术研究所下的一个研究实验室,专注于自然语言处理与机器学习领域的前沿技术研究。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)