

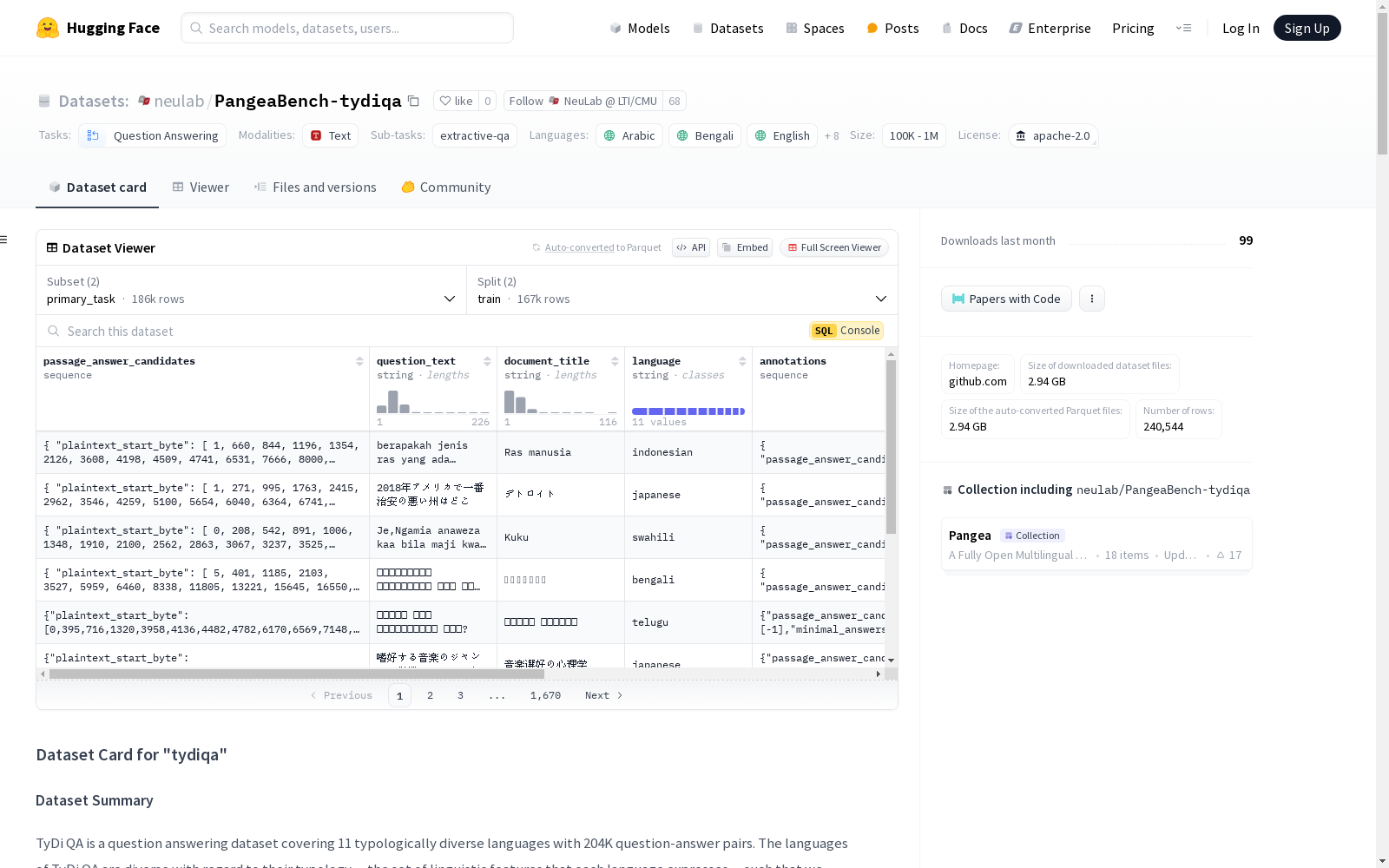
NeuLab @ LTI/CMU 本次发布的数据集 PangeaBench-tydiqa, TyDi QA是一个涵盖11种类型多样语言的问答数据集,包含204K个问答对。这些语言包括阿拉伯语、孟加拉语、英语、芬兰语、印度尼西亚语、日语、韩语、俄语、斯瓦希里语、泰卢固语和泰语。该数据集旨在提供一个现实的信息检索任务,并通过让提问者不知道答案来避免提示效应。数据直接在每种语言中收集,不经过翻译,旨在捕捉在仅英语语料库中找不到的语言现象。数据集分为两个任务:primary_task和secondary_task,每个任务都有自己的特征和数据划分。primary_task包括passage_answer_candidates、question_text、document_title、language、annotations、document_plaintext和document_url等特征。secondary_task包括id、title、context、question和answers等特征。该数据集采用Apache 2.0许可证。
Dataset card 内容:
Files and versions 内容:
关于 NeuLab @ LTI/CMU , NeuLab @ LTI/CMU是卡内基梅隆大学语言技术研究所下的一个研究实验室,专注于自然语言处理与机器学习领域的前沿技术研究。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)