

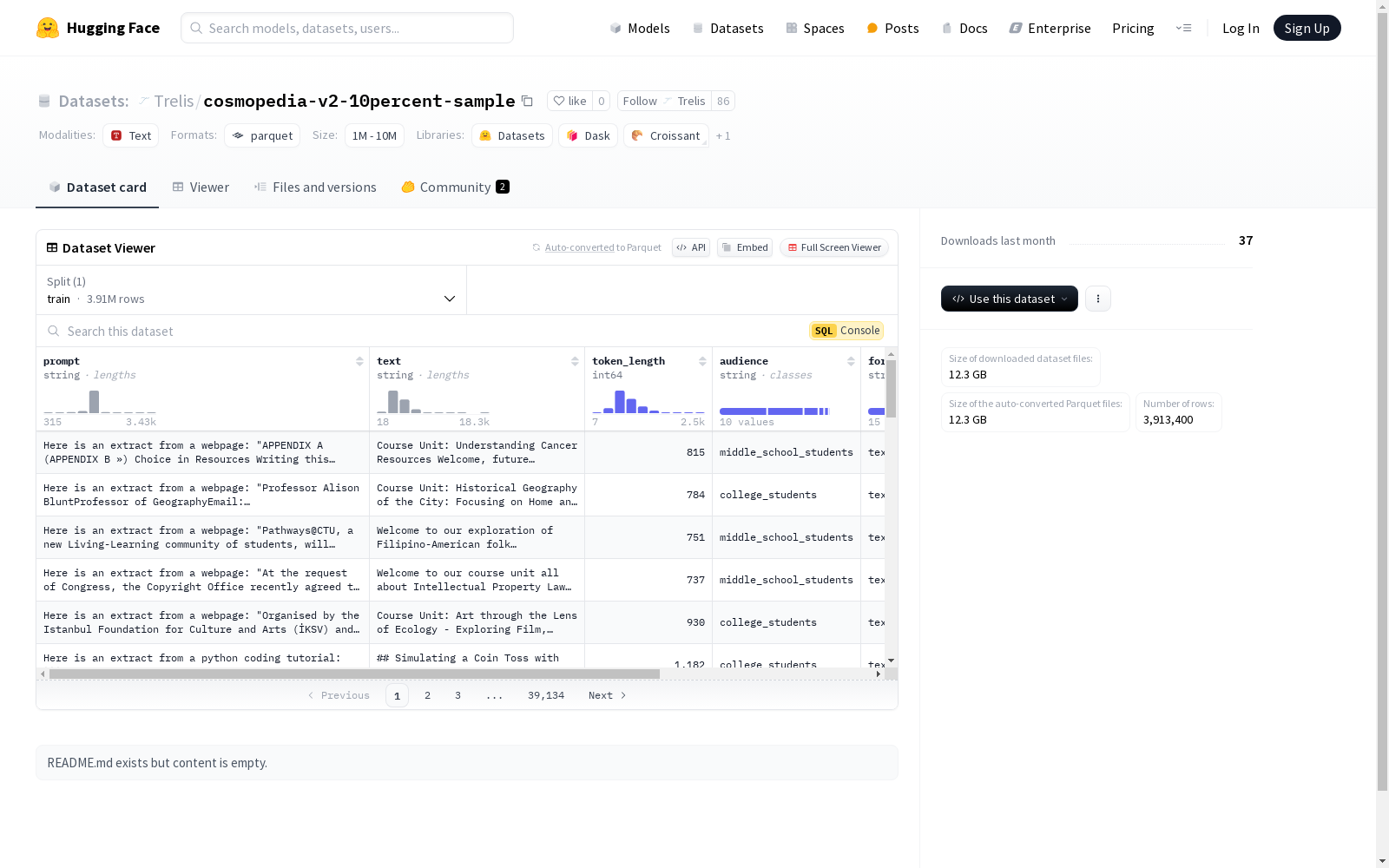
Trelis 本次发布的数据集 cosmopedia-v2-10percent-sample, 该数据集包含多个特征,包括prompt(提示)、text(文本)、token_length(标记长度)、audience(受众)、format(格式)和seed_data(种子数据),数据类型分别为字符串和整数。数据集分为训练集,包含3913400个样本,总大小为21250364074.7字节。数据集的配置名为default,数据文件路径为data/train-*。
查看cosmopedia-v2-10percent-sample
Dataset card 内容:
Files and versions 内容:
关于 Trelis , Trelis Research 提供高级大型语言模型微调脚本、推理指南、API模板以及视觉和语音转录微调服务。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)