

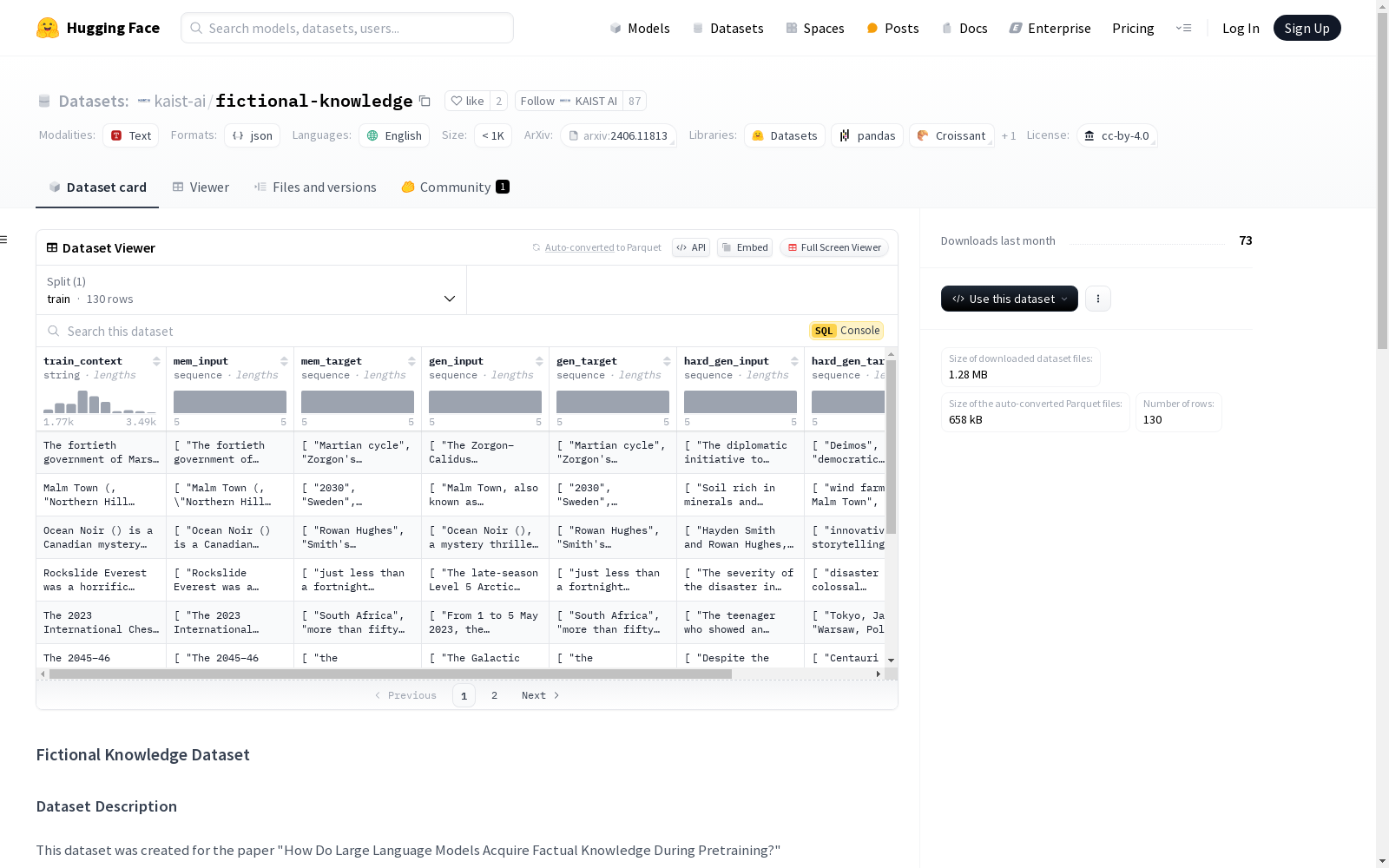
KAIST AI 本次发布的数据集 fictional-knowledge, 该数据集是为一篇关于大型语言模型在预训练期间如何获取事实知识的论文创建的,包含130条虚构知识条目及其对应的探测器,用于测试大型语言模型的事实知识获取能力。每个虚构知识条目由GPT-4生成,使用ECBD数据集的实例作为模板。数据集包含训练上下文、记忆输入和目标、语义泛化输入和目标、组合泛化输入和目标等字段。前40个条目还包括注入知识的9种不同释义。数据集为英文,格式为JSON。
Dataset card 内容:
Files and versions 内容:
关于 KAIST AI , KAIST AI是韩国科学技术院(KAIST)下属的人工智能研究机构,专注于人工智能技术的研究与开发,致力于推动韩国及全球AI领域的发展。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)