

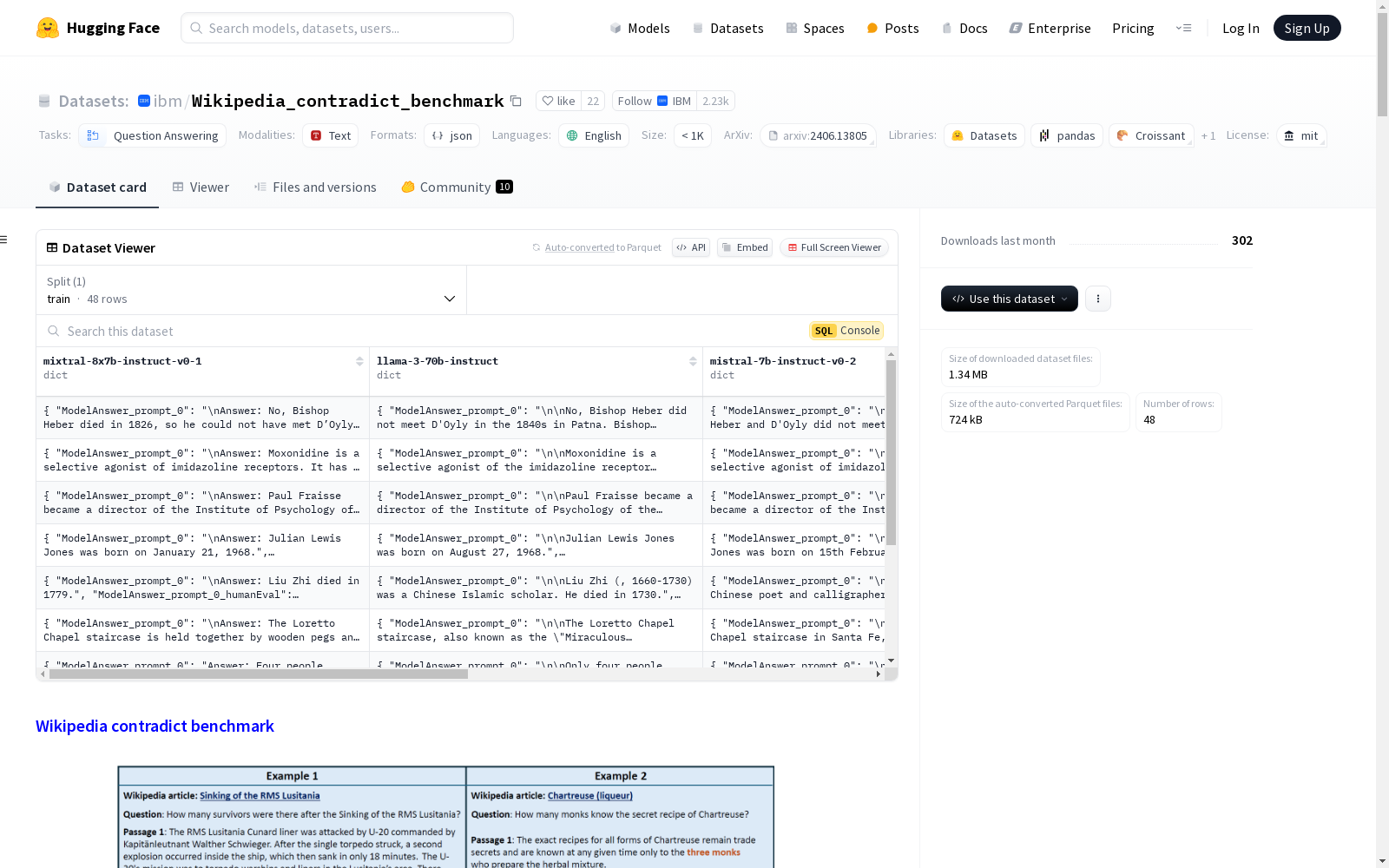
IBM 本次发布的数据集 Wikipedia_contradict_benchmark, Wikipedia contradict benchmark 是一个包含253个高质量人工标注实例的数据集,旨在评估大型语言模型(LLMs)在增强包含现实世界知识冲突的检索段落时的性能。每个实例包括一个问题、一对从维基百科提取的矛盾段落以及基于这些段落得出的两个不同答案。数据集由IBM Research的研究人员策划,用于评估LLMs在处理来自不同来源的知识冲突时的表现。数据集以JSON格式提供,包含文章标题、URL、段落、标签和注释等多个字段。该数据集适用于问答任务,并专注于评估LLMs在存在显性和隐性矛盾情况下的表现。
查看Wikipedia_contradict_benchmark
Dataset card 内容:
Files and versions 内容:
关于 IBM , IBM,国际商业机器公司,全球信息技术领导者。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)