

CLASSLA - CLARIN Knowledge Centre for South Slavic Languages 本次发布的数据集 ParlaSpeech-CZ, ParlaSpeech-CZ.v1.0数据集是从捷克议会记录的ParlaMint语料库和捷克议会的YouTube频道上的议会录音构建的。该数据集包含与转录文本中特定句子对应的音频段,并提供了单词级别的对齐,包括字符和毫秒的开始和结束偏移。数据集已经移除了超过30秒的序列,适用于大多数现代GPU。每个段都有一个标识符引用ParlaMint 4.0语料库。在HuggingFace版本中,只提供了部分元数据,如日期、发言者姓名、性别、出生年份、党派归属等。此外,该版本还包含一个`text_normalised`属性,去除了议会评论。
Dataset card 内容:
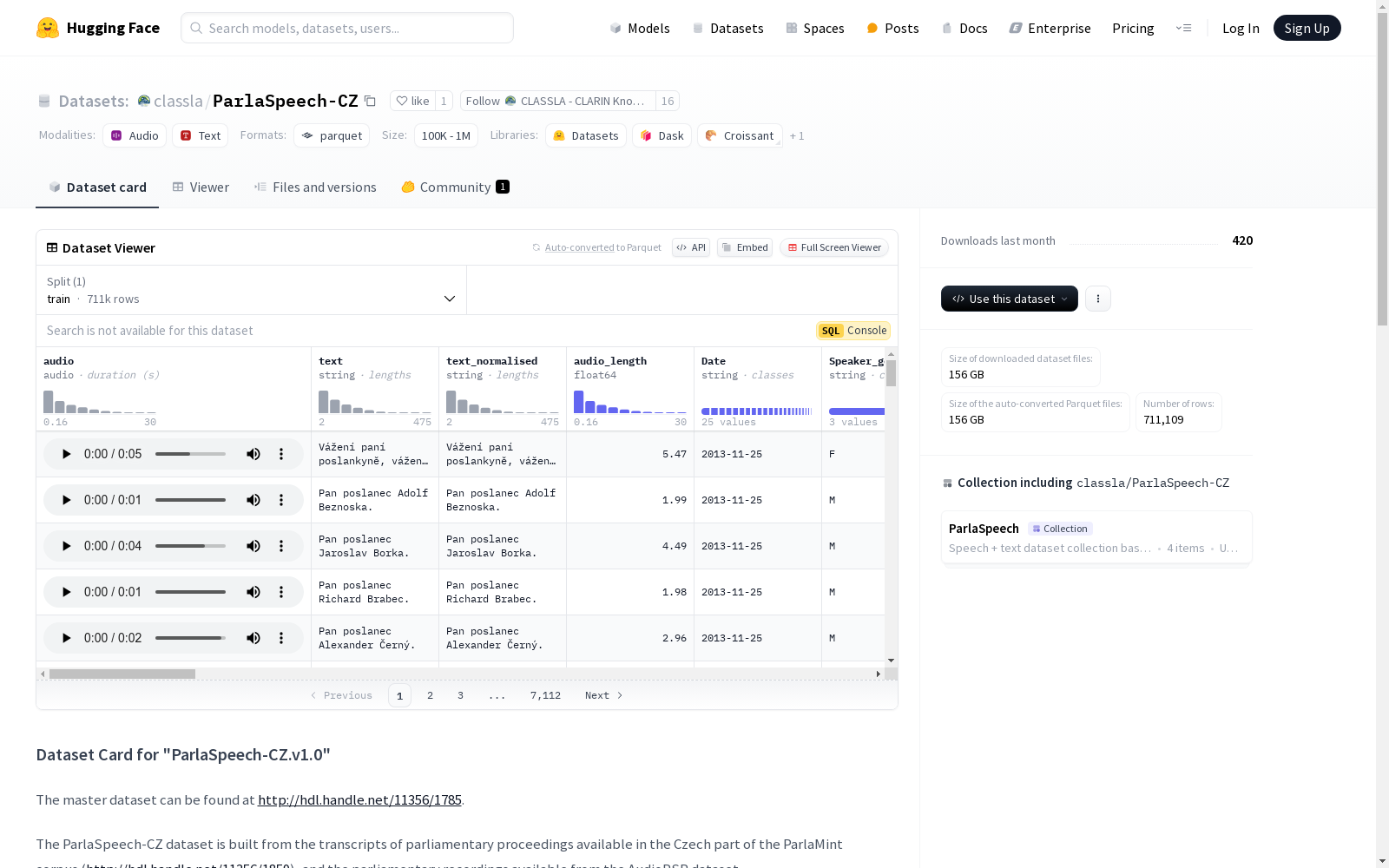
Files and versions 内容:
关于 CLASSLA - CLARIN Knowledge Centre for South Slavic Languages , CLASSLA是CLARIN(语言资源的计算机应用与研究基础设施)的一个知识中心,专注于南斯拉夫语言的语料库构建、工具开发和语言资源研究。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)