

Cohere For AI 本次发布的数据集 m-ArenaHard, m-ArenaHard数据集是一个多语言的大型语言模型(LLM)评估集。该数据集通过使用Google Translate API v3将原本仅限英语的LMarena(前身为LMSYS)arena-hard-auto-v0.1测试数据集的提示翻译成22种语言而创建。原始的英语提示由Li等人(2024年)创建,包含从Chatbot Arena收集的500个具有挑战性的用户查询。该数据集总共包含23种语言,每种语言有500个示例。数据集的字段包括question_id、cluster、category和prompt。该数据集由Cohere For AI发布,并根据Apache 2.0许可证进行许可。
Dataset card 内容:
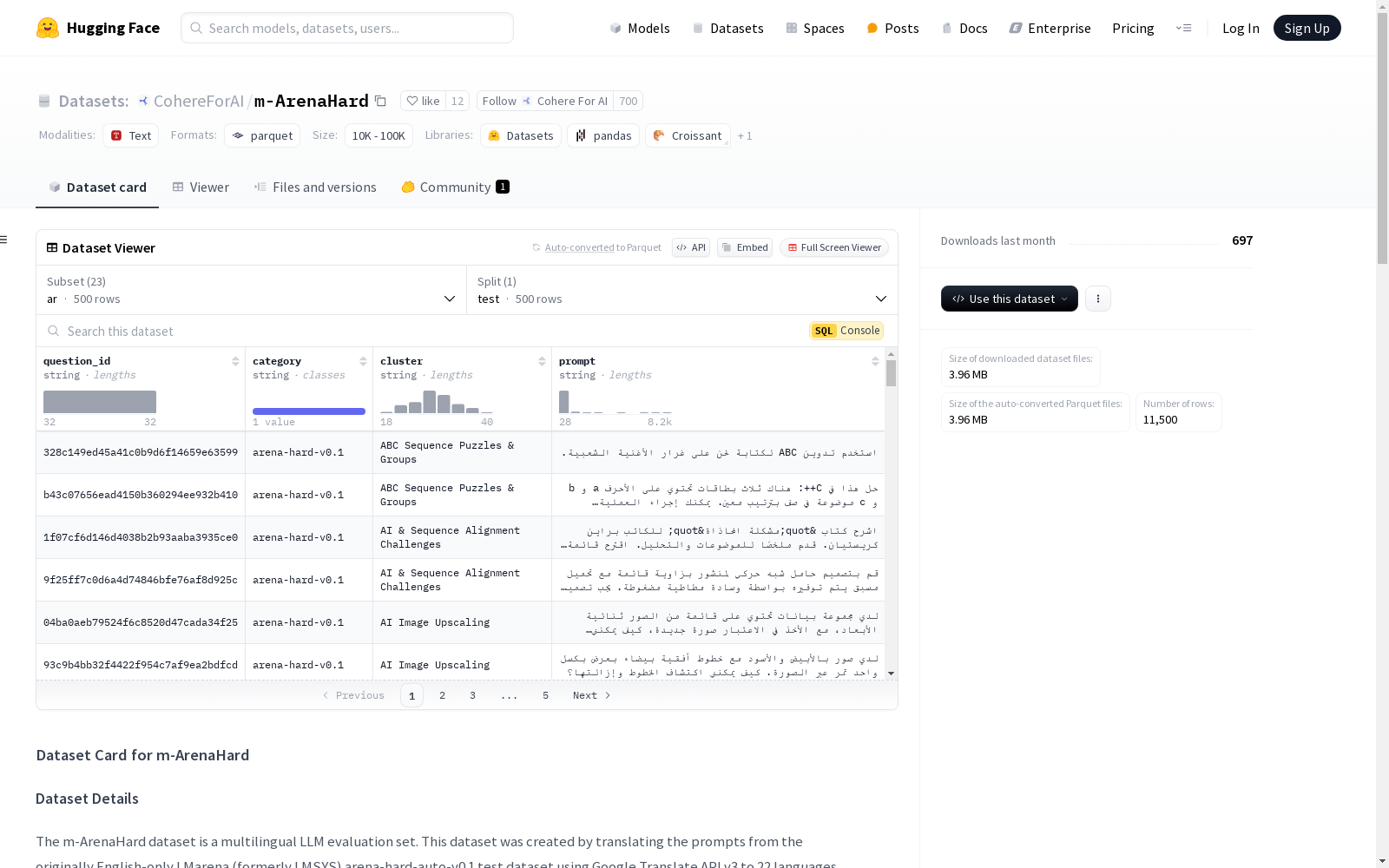
Files and versions 内容:
关于 Cohere For AI , Cohere For AI是一个非营利性研究实验室,致力于解决复杂的机器学习问题,通过开放合作推动机器学习研究的实质性进展,并支持通过不同媒介进行科学交流的多种视角,促进负责任的创新。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)