

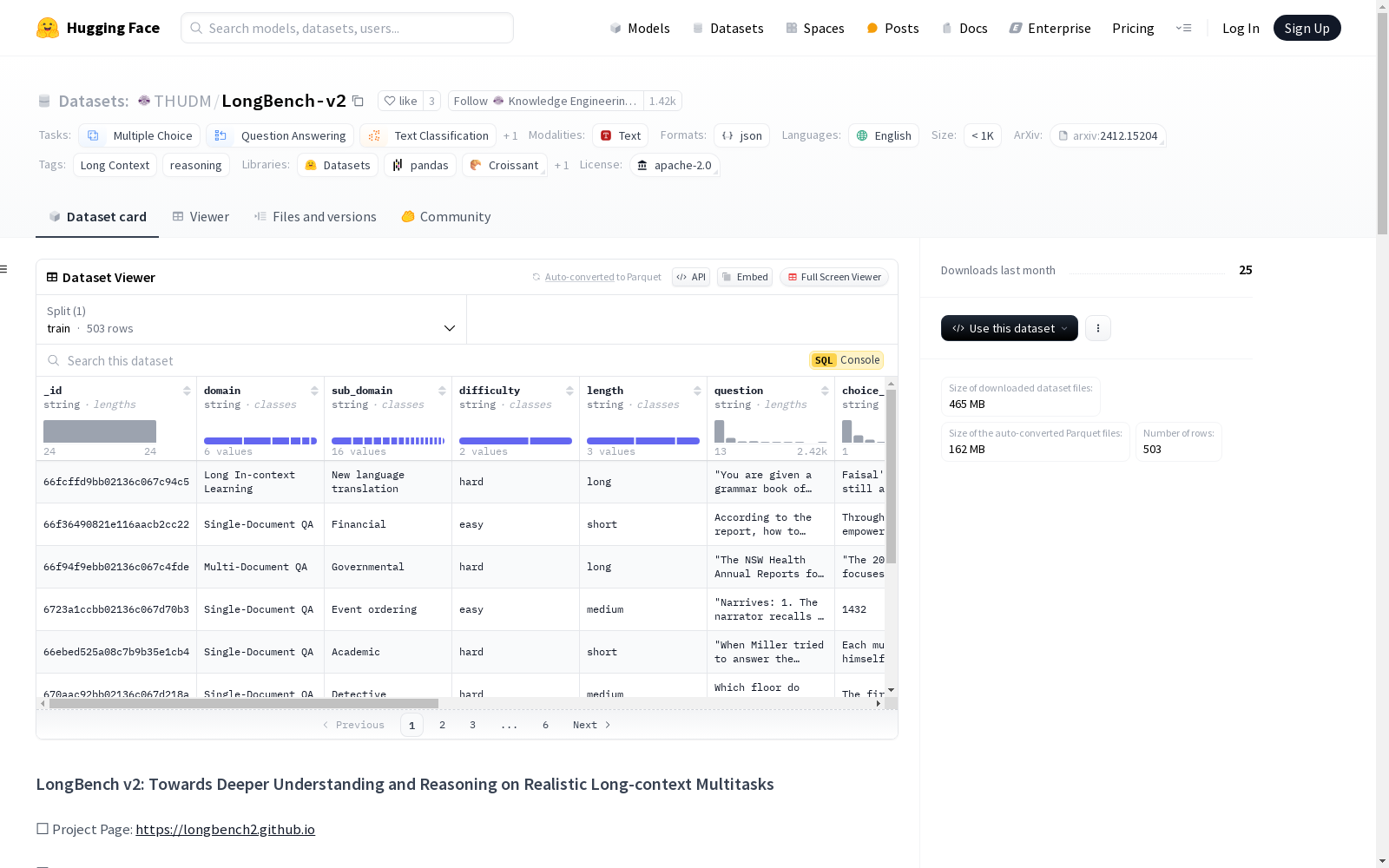
Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University 本次发布的数据集 LongBench-v2, LongBench v2 是一个用于评估大型语言模型(LLMs)处理长上下文问题的能力的数据集。该数据集设计用于测试模型在需要深度理解和推理的真实多任务场景中的表现。其特点包括:1)上下文长度从8k到2M字不等,大部分在128k以下;2)难度较高,即使是使用搜索工具的人类专家在短时间内也无法正确回答;3)覆盖多种现实场景;4)采用多选题格式以确保评估的可靠性。数据集包含503个具有挑战性的多选题,涉及六个主要任务类别:单文档问答、多文档问答、长上下文学习、长对话历史理解、代码库理解和长结构化数据理解。数据集的质量和难度通过自动化和手动审查流程来保证,结果显示人类专家在15分钟内只能达到53.7%的准确率,而最佳模型直接回答问题时准确率为50.1%,包含更长推理的模型则达到57.7%。
Dataset card 内容:
Files and versions 内容:
关于 Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University , 清华大学知识工程研究室(KEG)和数据挖掘小组(THUDM)专注于大型语言模型研究与应用。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)