

本次发布的数据集 smoltalk-chinese, smoltalk-chinese 是一个参考 SmolTalk 数据集构建的中文微调数据集,旨在为大型语言模型(LLM)的训练提供高质量的合成数据支持。该数据集全部由合成数据组成,涵盖超过70万条数据,专门设计用于提升中文大型语言模型在多种任务上的表现,增强模型的多功能性和适应性。数据集由多个部分组成,包括参考magpie-ultra的任务类型、参考smoltalk的其它任务类型、模拟日常生活中的对话风格以及来自Math23K中文版的数学题数据。数据集的生成过程严格遵循高标准,确保数据的质量和多样性。实验验证表明,基于smoltalk-chinese微调的模型在多个指标上表现出显著优势。
Dataset card 内容:
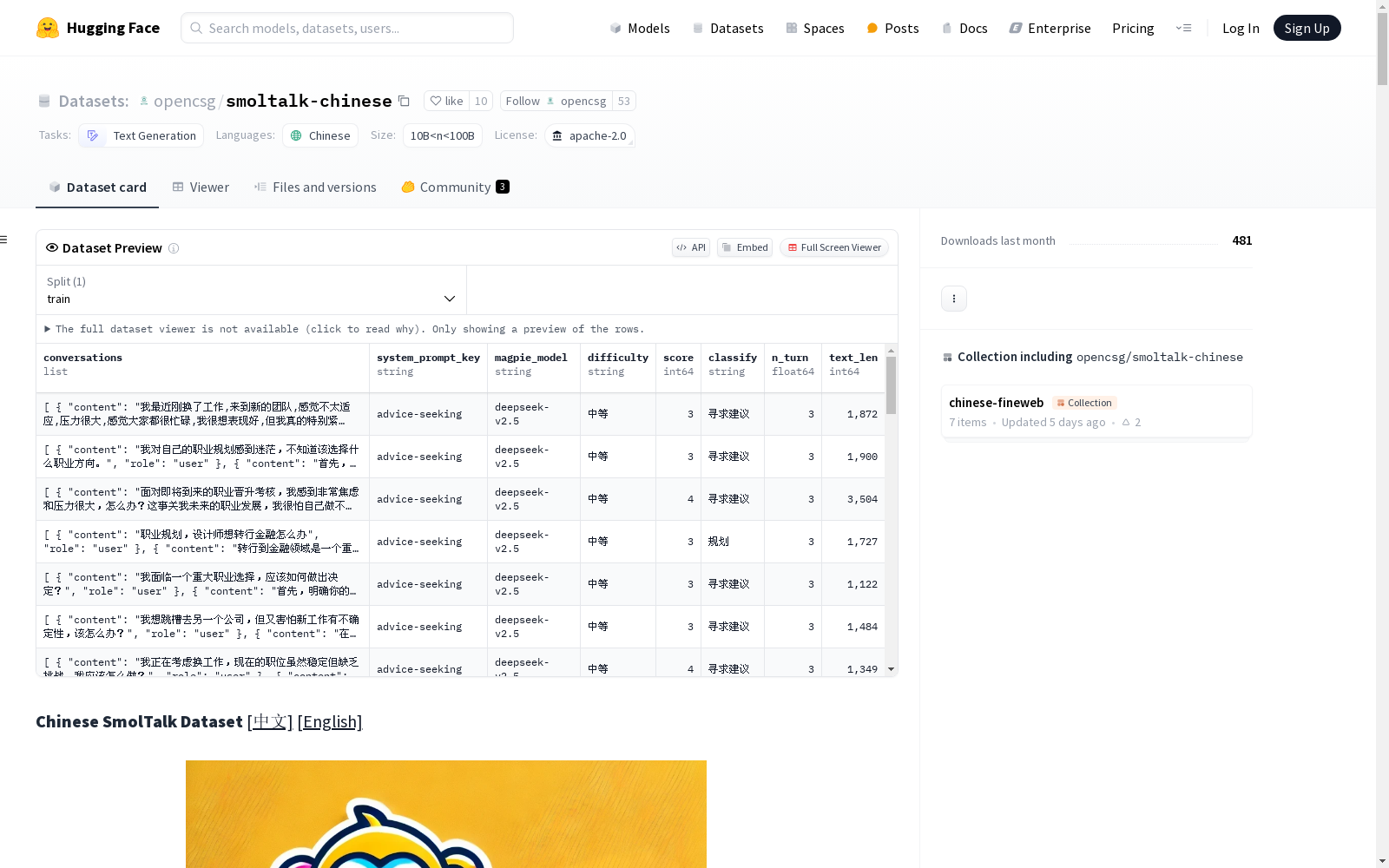
Files and versions 内容:
关于 , 国庆学校是一所位于中国的教育机构,专注于提供基础教育服务。学校致力于培养学生的综合素质,注重学术与品德的全面发展。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)