

本次发布的数据集 qwark-corpus, Qwark Corpus是一个包含超过13亿高质量互联网文本的数据集,基于HuggingFaceTB/smollm-corpus的fineweb-edu-dedup子集和FineMath-4+数据集构建。数据集经过多步过滤,包括选择高质量样本、移除过长的文本、添加TED演讲文本等步骤,最终包含999,245个样本,总大小为5.29GB。数据集的特征包括文本、ID和元数据,元数据中包括日期、文件路径、语言、分数等多个字段。
Dataset card 内容:
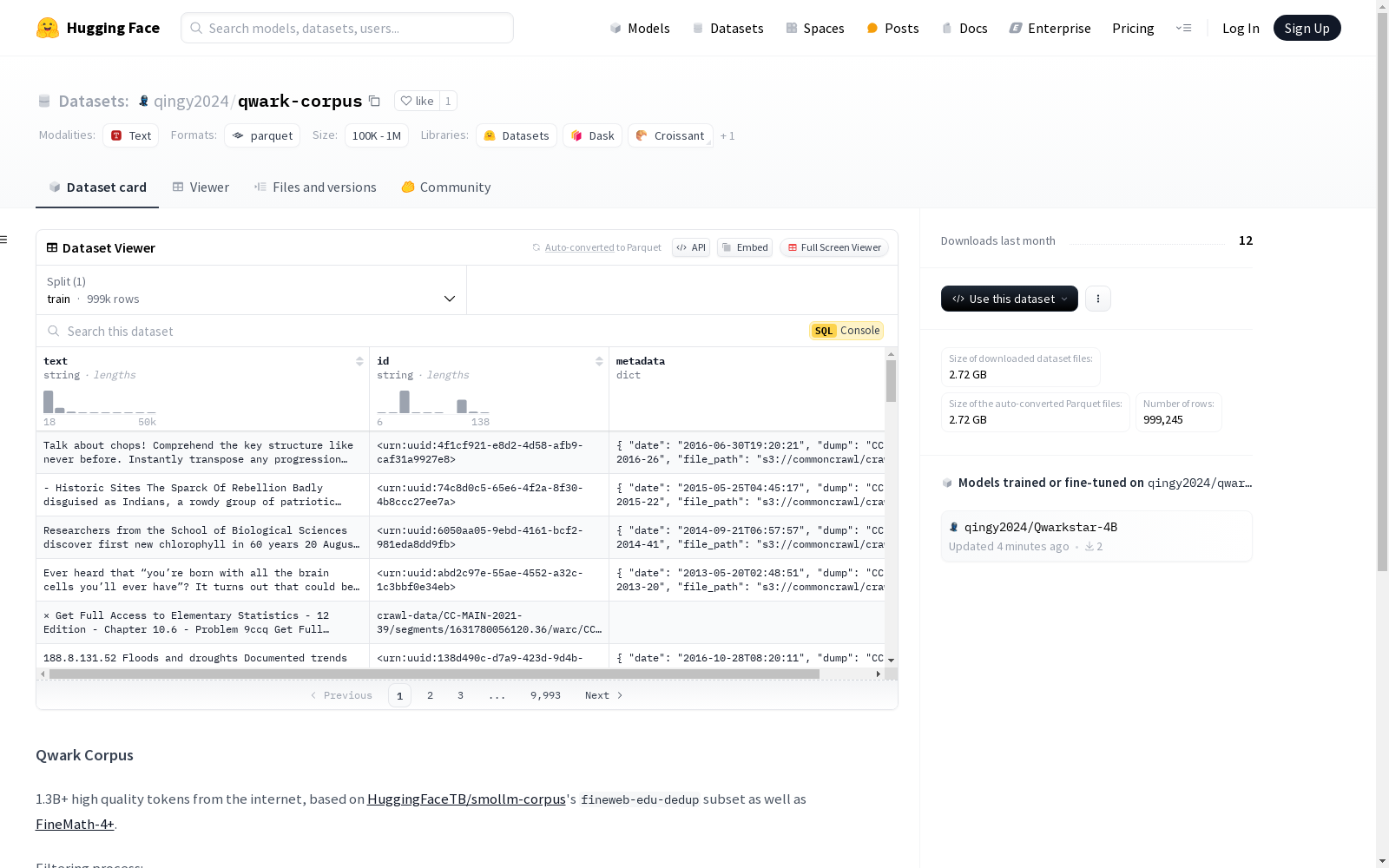
Files and versions 内容:
关于 , 国庆学校是一所位于中国的教育机构,专注于提供基础教育服务。学校致力于培养学生的综合素质,注重学术与品德的全面发展。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)