

MBZUAI UGRIP Statement Tuning 本次发布的数据集 wiki_lingua_instruction, 该数据集包含多种语言版本(如阿拉伯语、德语、英语、西班牙语、法语、印地语、印尼语、意大利语、葡萄牙语、俄语、土耳其语、越南语和中文),每个语言版本的数据集都包含两个特征:instruction(指令)和output(输出),数据类型均为字符串。每个语言版本的数据集仅包含dev分割,且每个分割都有对应的字节数和示例数。数据集的大小和下载大小也因语言版本而异。
Dataset card 内容:
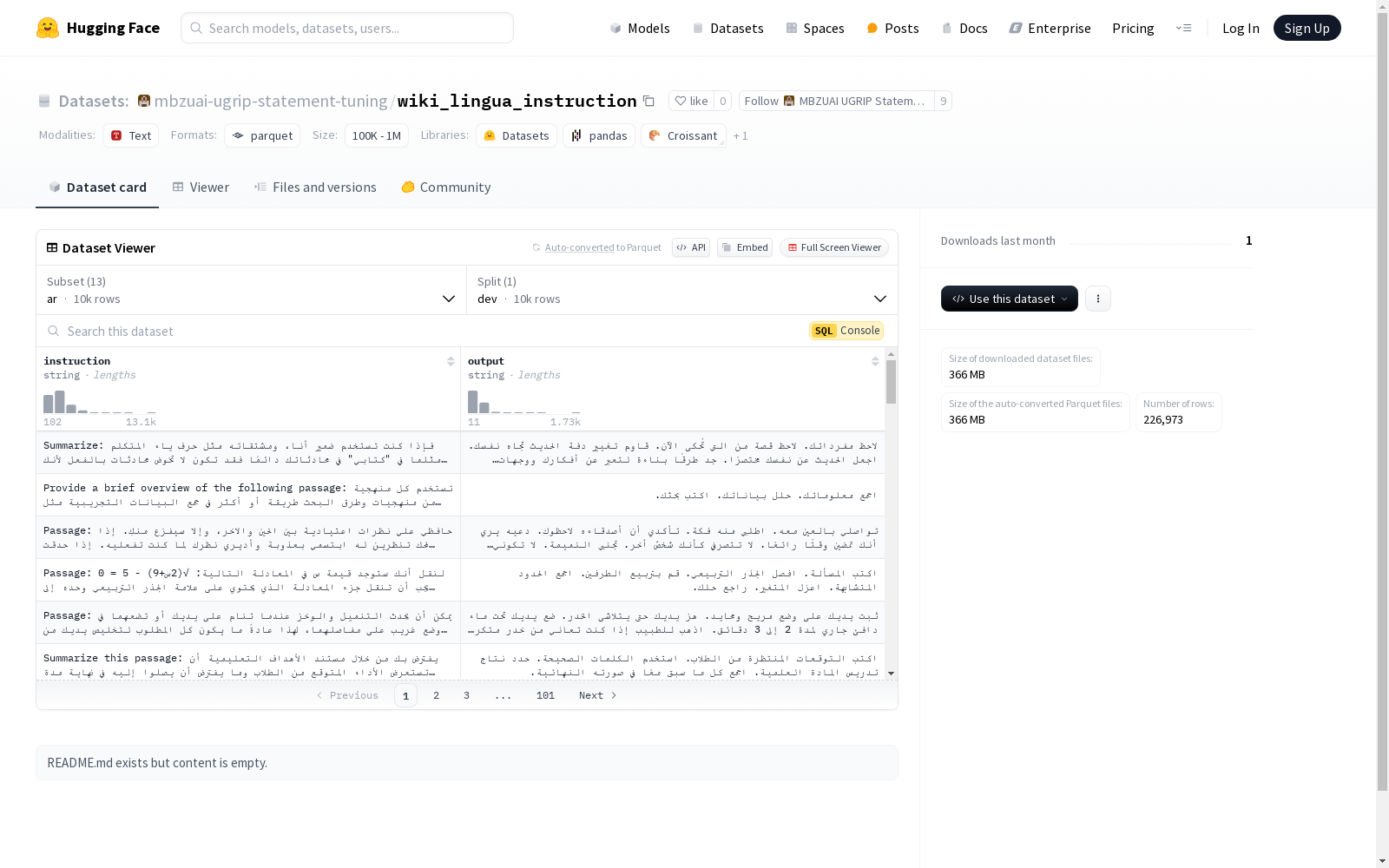
Files and versions 内容:
关于 MBZUAI UGRIP Statement Tuning , MBZUAI UGRIP Statement Tuning是穆罕默德·本·扎耶德人工智能大学(MBZUAI)的一个项目,旨在通过优化研究生创新计划的陈述,提升学生的研究提案质量和申请成功率。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)