

SpeechBrain 本次发布的数据集 LargeScaleASR, LargeScaleASR数据集是一个包含25,000小时转录和异构英语语音识别数据的数据集,适用于研究和商业用途。数据集由6个子集组成,分别是large、medium、small、clean、dev和test,每个子集包含不同小时数的转录语音数据。数据集主要用于自动语音识别任务,特别是鲁棒语音识别和噪声语音识别。数据集的创建涉及多个现有数据集的混合,包括VoxPopuli、LibriHeavy、Librispeech、YODAS、Peoples Speech和CommonVoice 18.0。数据集中的文本和音频都经过了标准化处理,以确保数据的一致性和质量。
Dataset card 内容:
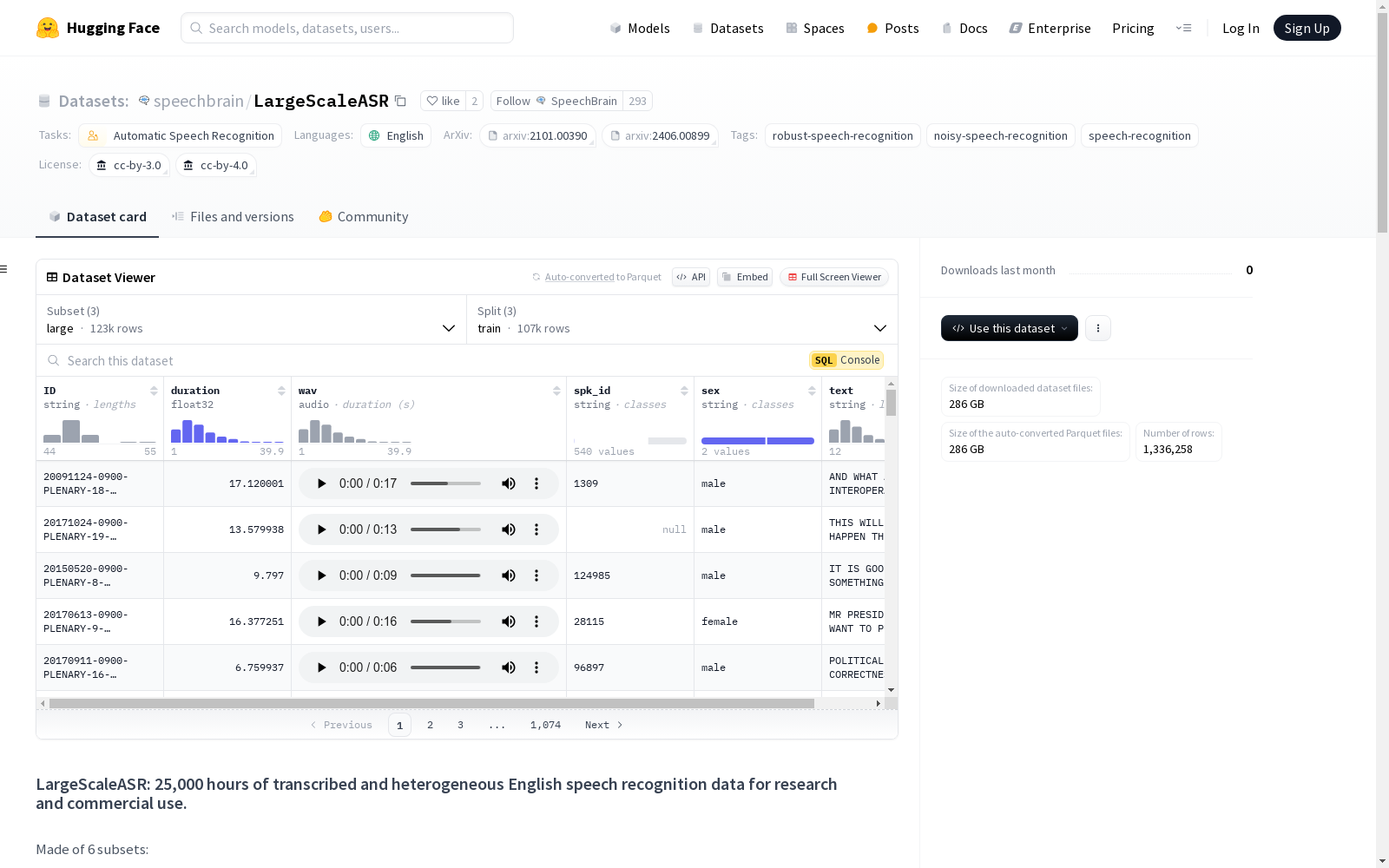
Files and versions 内容:
关于 SpeechBrain , SpeechBrain是一个专注于自动语音识别(ASR)、语音合成(TTS)和语音转换等语音技术研究的开源工具包和深度学习框架。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)