

InternLM 本次发布的数据集 Condor-SFT-20K, Condor是一个两阶段的数据合成引擎,旨在生成高质量的监督微调数据,以增强大型语言模型的对话能力。该数据集包括英文和中文内容,适用于文本生成任务。Condor通过引入世界知识树和自我反思精炼策略,能够大规模生成高质量的SFT数据。实验结果表明,仅使用20K Condor生成的样本进行微调的模型,其性能优于其他RLHF训练的模型。
Dataset card 内容:
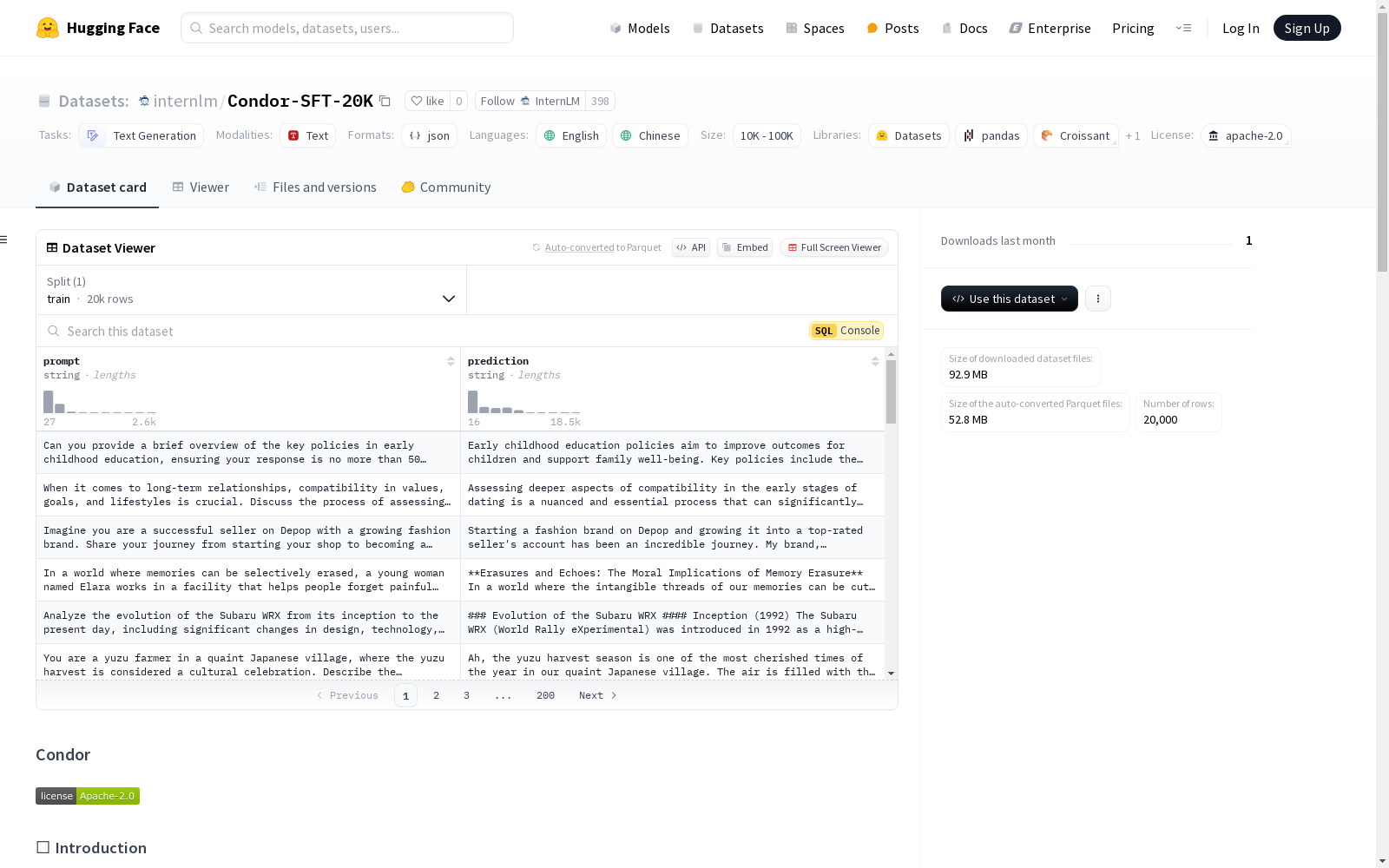
Files and versions 内容:
关于 InternLM , InternLM 是由上海人工智能实验室主要开发,专注于开源高质量大型语言模型及全栈开发应用工具链的组织。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)