

本次发布的数据集 uzbek-speech-corpus, 乌兹别克语语音语料库(USC)是由ISSAI和塔什干信息技术大学计算机系统系图像与语音处理实验室合作开发的。该语料库包含958个不同说话者的105小时转录音频。为确保高质量,语料库经过母语者的手动检查。USC主要用于自动语音识别(ASR),但也适用于语音合成和语音翻译等其他任务。据我们所知,USC是第一个在Creative Commons Attribution 4.0 International许可下开放给学术和商业用途的乌兹别克语语音语料库。我们期望USC将成为乌兹别克语ASR研究的基准数据集,并为语音研究社区提供宝贵的资源。
Dataset card 内容:
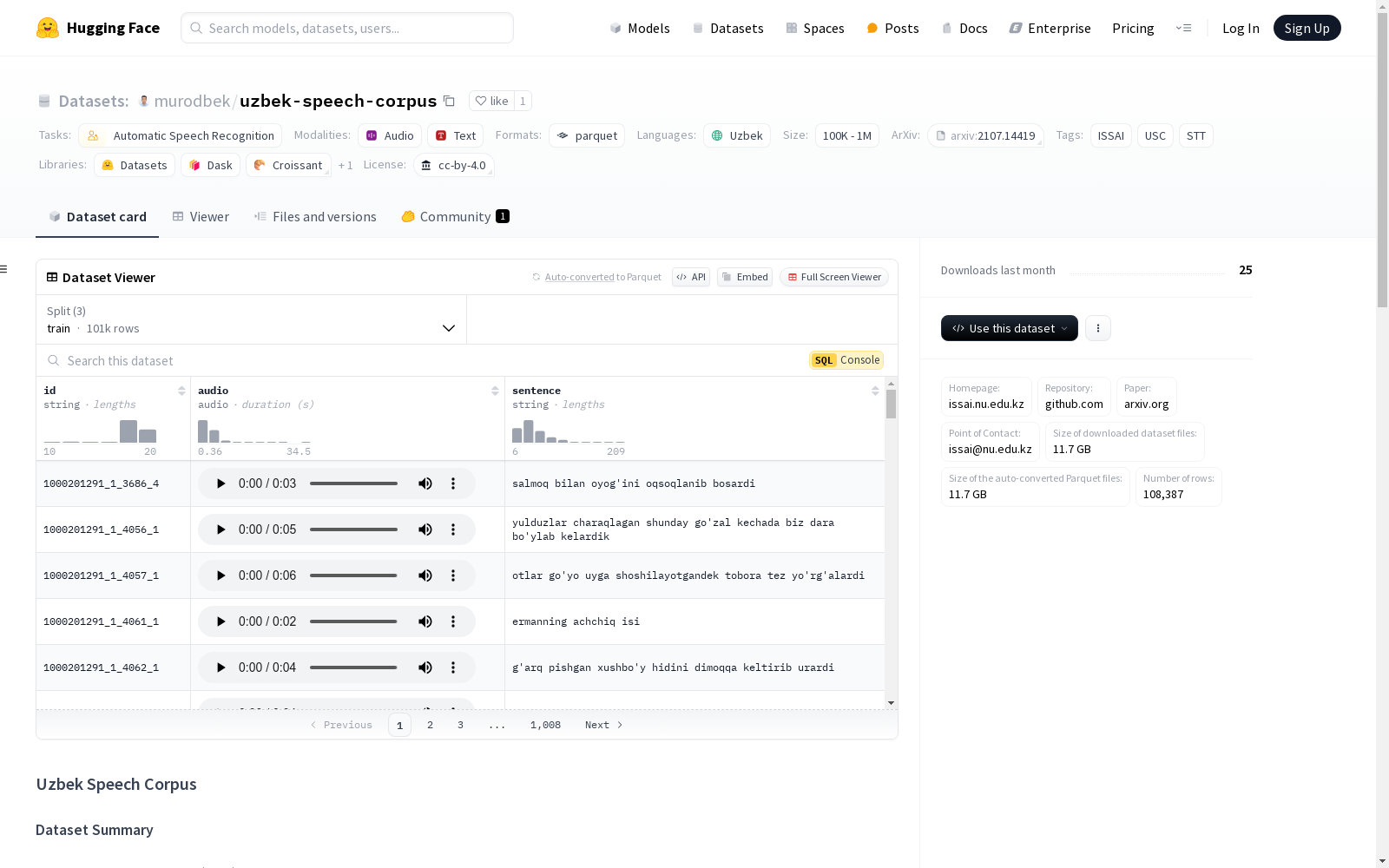
Files and versions 内容:
关于 , 国庆学校是一所位于中国的教育机构,专注于提供基础教育服务。学校致力于培养学生的综合素质,注重学术与品德的全面发展。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)