

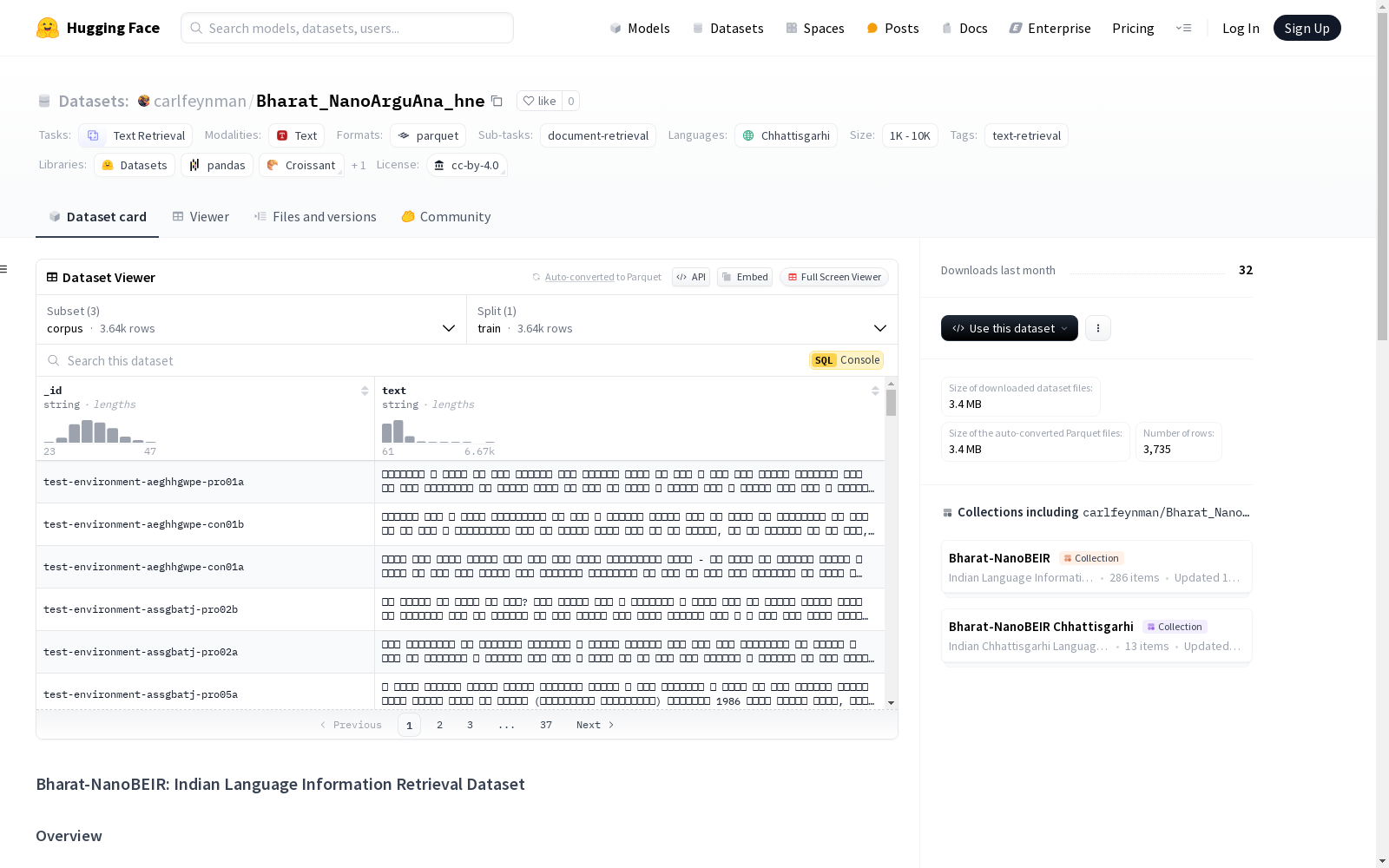
本次发布的数据集 Bharat_NanoArguAna_hne, 该数据集是Bharat-NanoBEIR集合的一部分,专门为印度语言的信息检索任务设计,特别是Chhattisgarhi语言。数据集源自NanoBEIR项目,提供了包含50个查询和最多10K文档的较小版本的BEIR数据集。该数据集是NanoArguAna数据集的Chhattisgarhi版本,专门为信息检索任务进行了翻译和适配。数据集包含三个主要部分:Corpus(文档集合)、Queries(搜索查询)和QRels(查询与文档的相关性判断)。数据集适用于信息检索系统的开发、多语言搜索能力的评估、跨语言信息检索研究以及Chhattisgarhi语言模型的基准测试。
Dataset card 内容:
Files and versions 内容:
关于 , 国庆学校是一所位于中国的教育机构,专注于提供基础教育服务。学校致力于培养学生的综合素质,注重学术与品德的全面发展。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)