

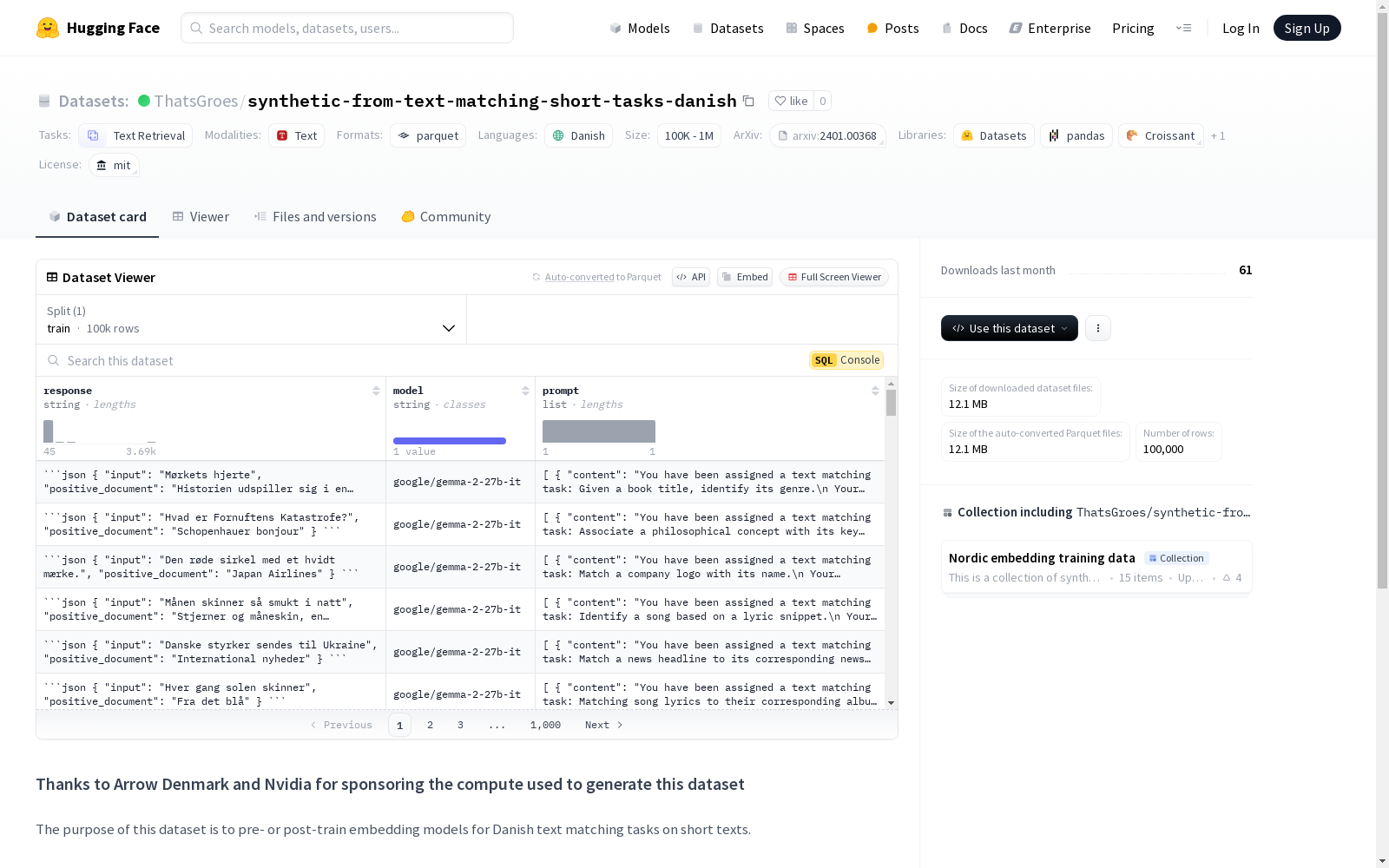
本次发布的数据集 synthetic-from-text-matching-short-tasks-danish, 该数据集的目的是用于丹麦语短文本匹配任务的嵌入模型的预训练或后训练。数据集包含100,000个样本,这些样本是由gemma-2-27b-it模型生成的。每个样本的prompt列显示了给大型语言模型(LLM)的提示,而response列显示了LLM的输出。样本是从一个种子任务中随机抽取的,该任务来源于一个特定的HuggingFace数据集。数据生成过程遵循了一篇论文中描述的方法。
查看synthetic-from-text-matching-short-tasks-danish
Dataset card 内容:
Files and versions 内容:
关于 , 国庆学校是一所位于中国的教育机构,专注于提供基础教育服务。学校致力于培养学生的综合素质,注重学术与品德的全面发展。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)