

INESC-ID Lisboa 本次发布的数据集 GroundCap, GroundCap是由INESC-ID Lisboa和Universidade de Lisboa的研究人员创建的一个视觉定位图像字幕数据集。该数据集包含来自77部电影的52,016张图像,其中包含344个由人类注释和52,016个自动生成的字幕。每个字幕都与检测到的对象(132个类别)和动作(51个类别)相关联,使用一个标签系统保持对象身份,同时将动作链接到相应的对象。该数据集旨在解决图像字幕系统中缺乏将描述性文本链接到特定视觉元素的问题。
Dataset card 内容:
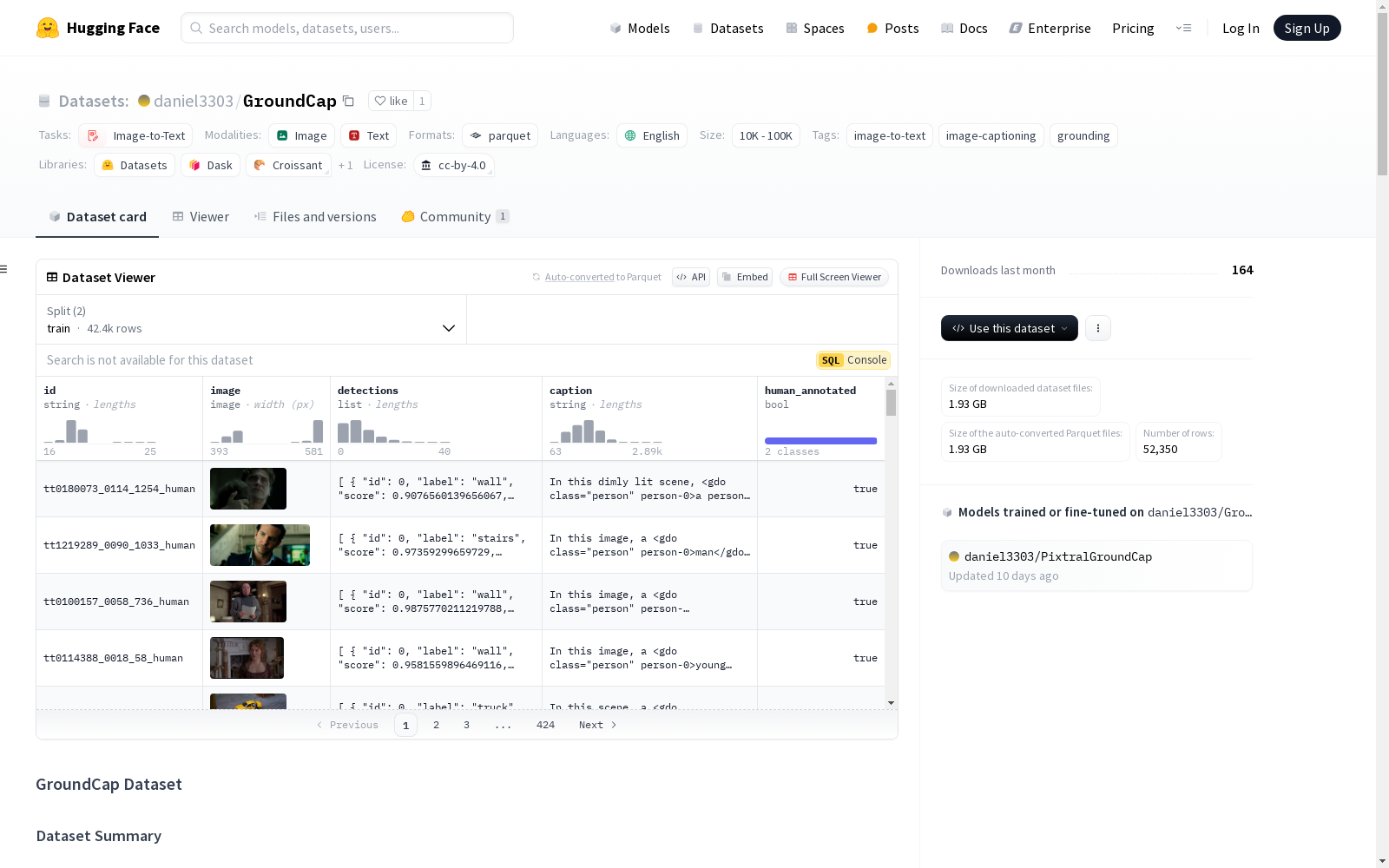
Files and versions 内容:
关于 INESC-ID Lisboa , -
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)