

TartuNLP 本次发布的数据集 pale-madlad-data, 该数据集包含了针对低资源芬兰-乌戈尔语系的段落级机器翻译数据,具体包括omamedia、vepkar、wikipedia和ylefi四种语言的数据。vepkar数据集还有一个公开的语料库,用于维普和卡累利阿语言的研究和应用。
Dataset card 内容:
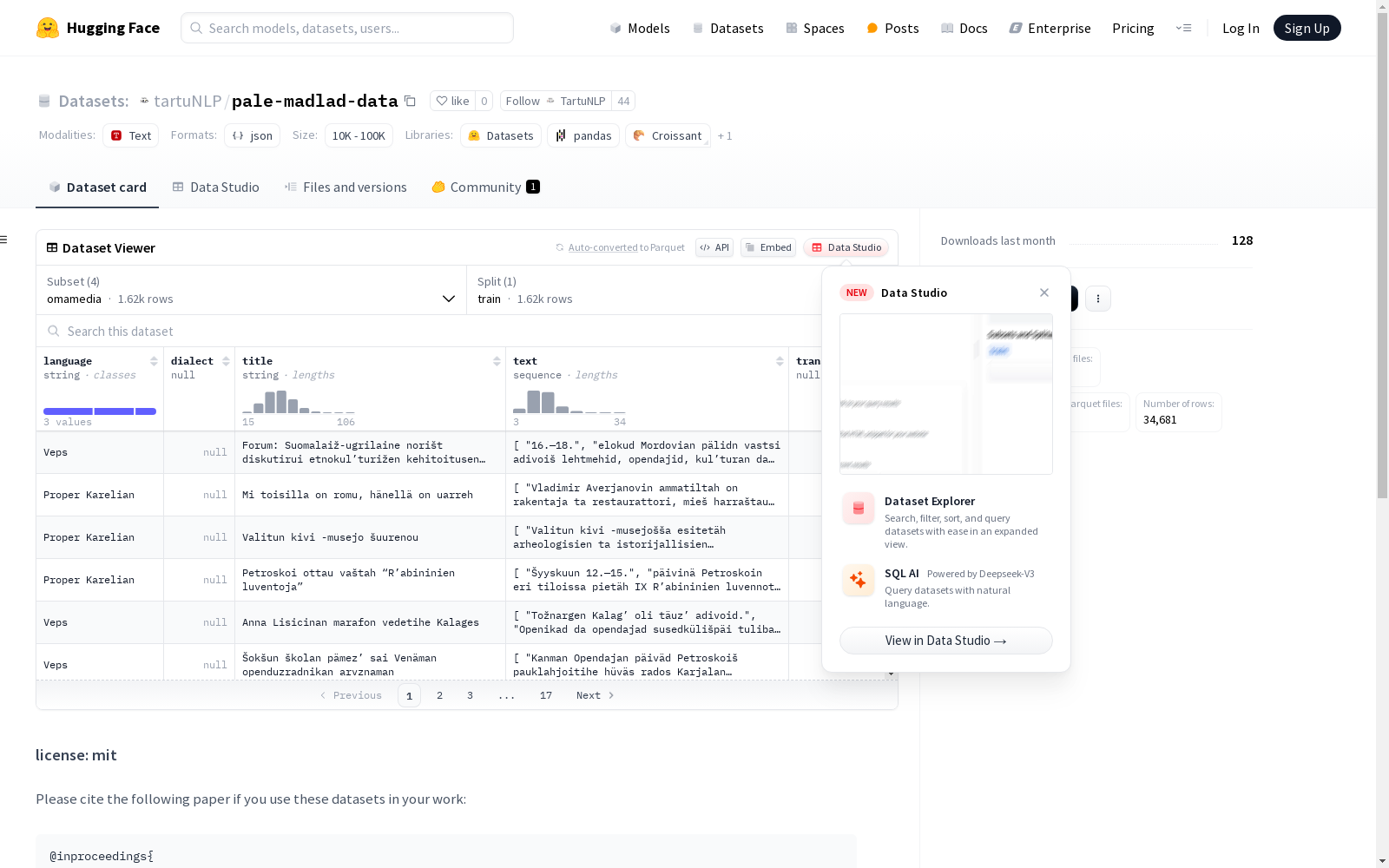
Files and versions 内容:
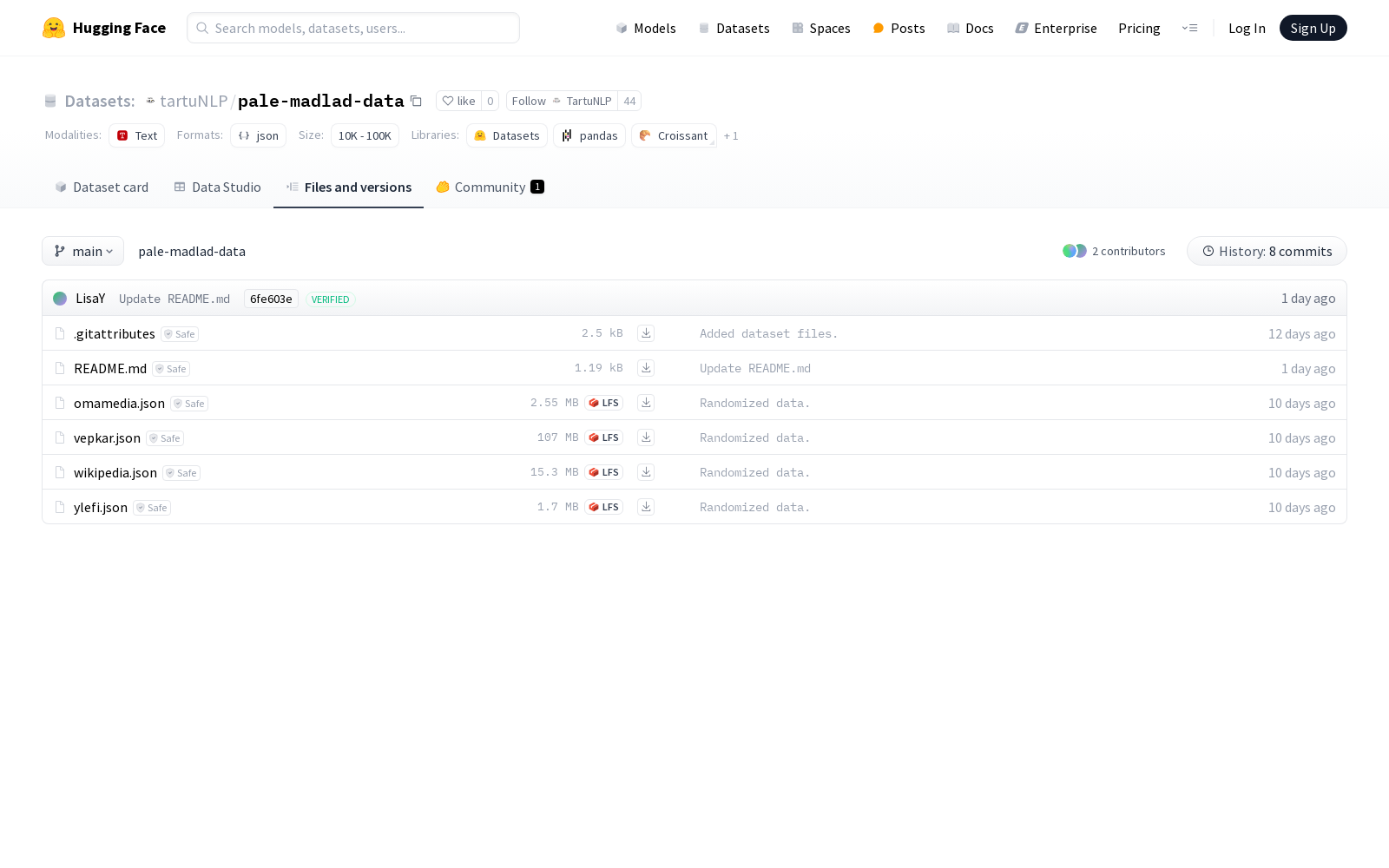
关于 TartuNLP , TartuNLP是一个专注于自然语言处理领域的研究组织,致力于开发先进的NLP技术和工具,以促进语言技术的创新和应用。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)