

NADSOFT 本次发布的数据集 test_dataset_dialect_SLM, 该数据集包含以下字段:唯一标识符_id、节目名称program、文本内容text、方言dialect、审核后的文本reviewed_text和清洗后的文本clean_text。数据集被划分为测试集,包含5600个示例,大小为2,782,109字节。数据集的下载大小为1,410,715字节。
Dataset card 内容:
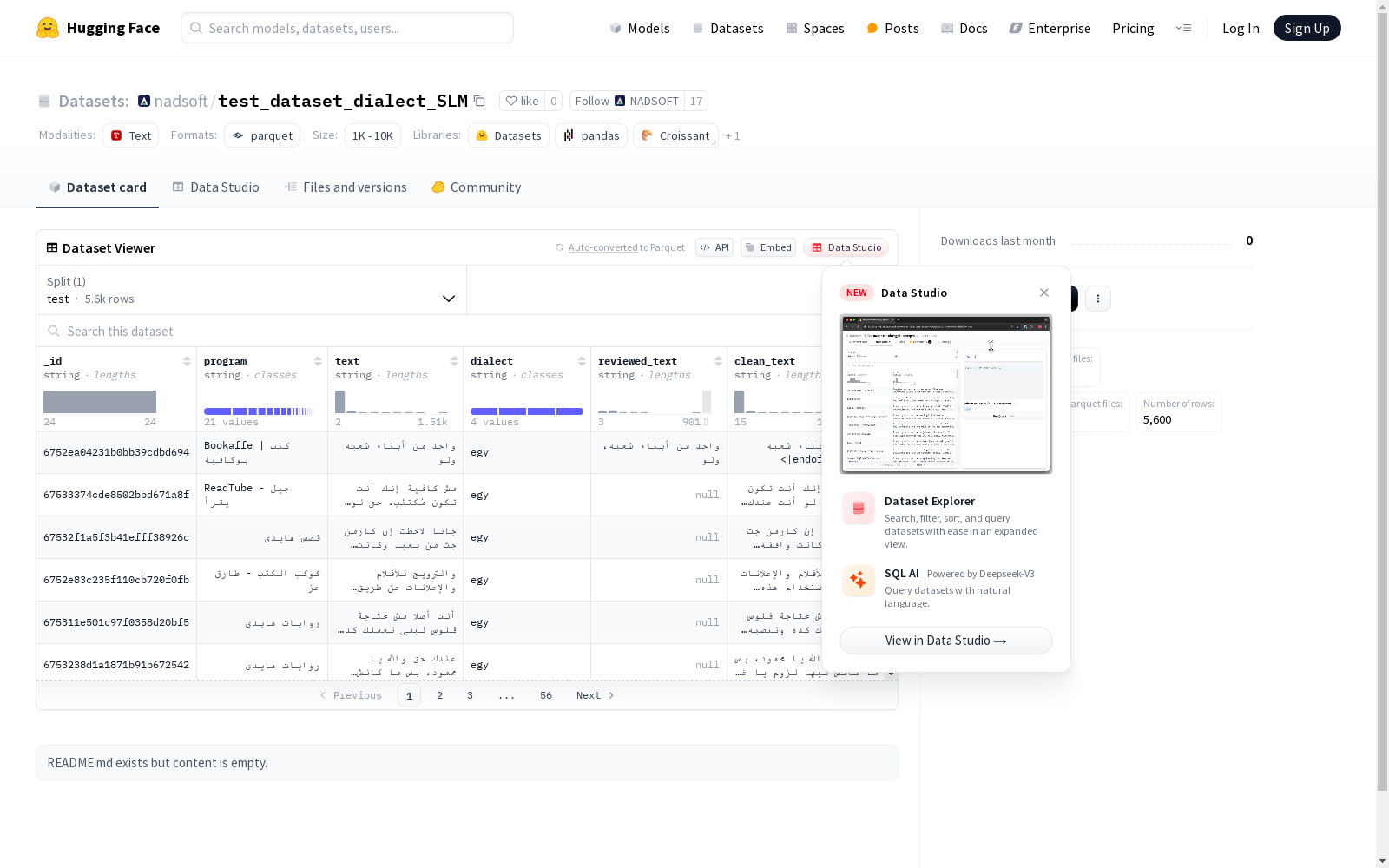
Files and versions 内容:
关于 NADSOFT , NADSOFT是一家致力于革新阿拉伯语AI模型领域的先锋公司,专注于提升为阿拉伯语定制的AI模型性能,致力于研究和训练尖端的AI模型如语言模型(LLM)、自动语音识别(ASR)等,并希望在阿拉伯世界及更广泛的中东和北非地区引领AI革命。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)