

LiLab 本次发布的数据集 MMLU-ProX, MMLU-ProX是一个多语言基准测试,它扩展了MMLU-Pro,覆盖了13种类型多样的语言。这个数据集是为了评估大型语言模型在不同语言和文化背景下的推理能力而设计的。它包含了问题、选项、答案以及相关元数据,并提供了验证集和测试集。
Dataset card 内容:
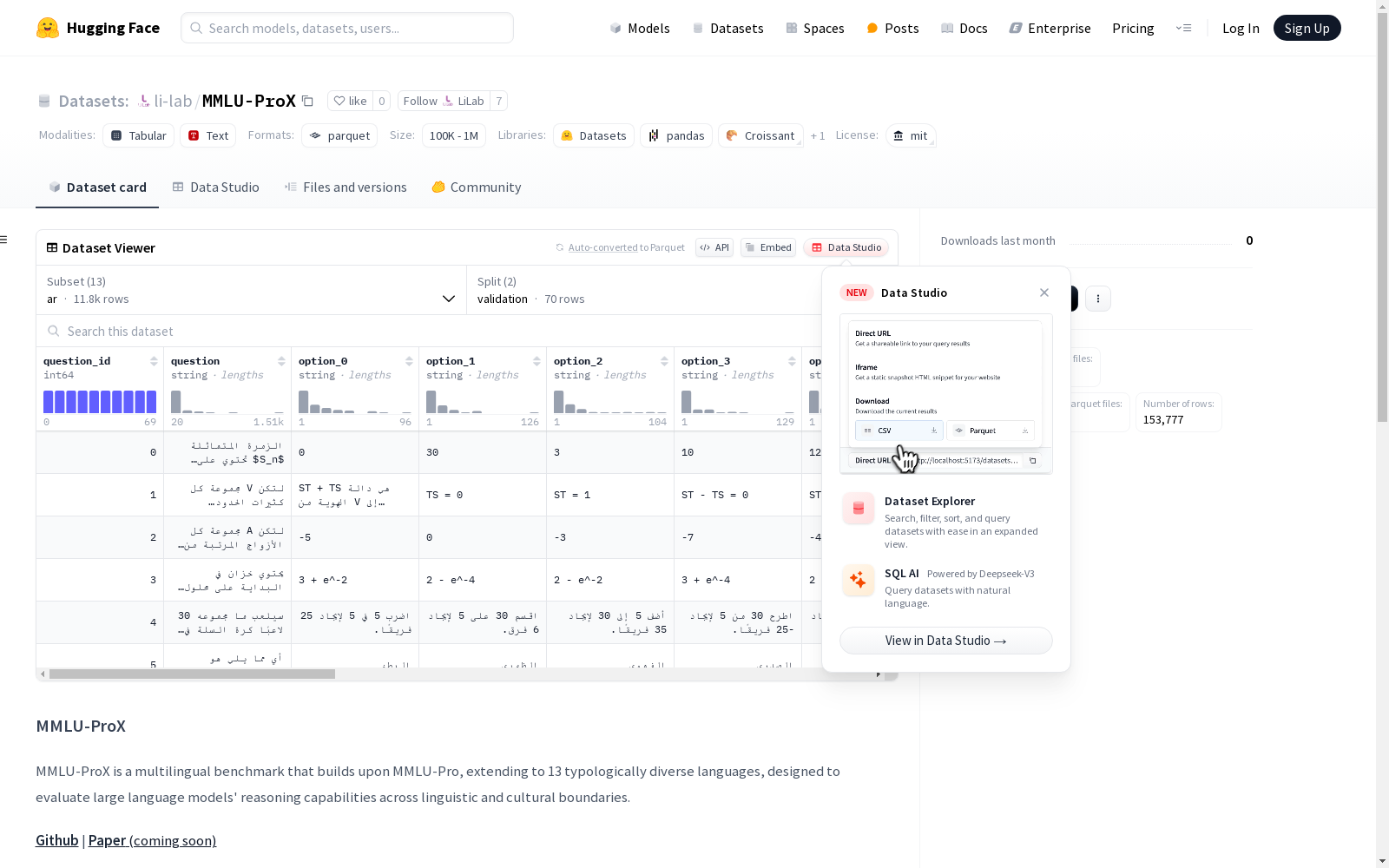
Files and versions 内容:
关于 LiLab , LiLab是一个致力于人工智能和机器学习研究的实验室,专注于推动相关技术的创新与应用,旨在为全球科研和技术发展提供动力。
关于 HuggingFace , Hugging Face是一个机器学习社区协作平台,专注于模型、数据集和应用程序的创建、发现和协作。该平台支持多种数据类型,包括文本、图像、视频、音频和3D数据,并提供开源工具和付费计算及企业解决方案。



_1769672084863.jpg)