

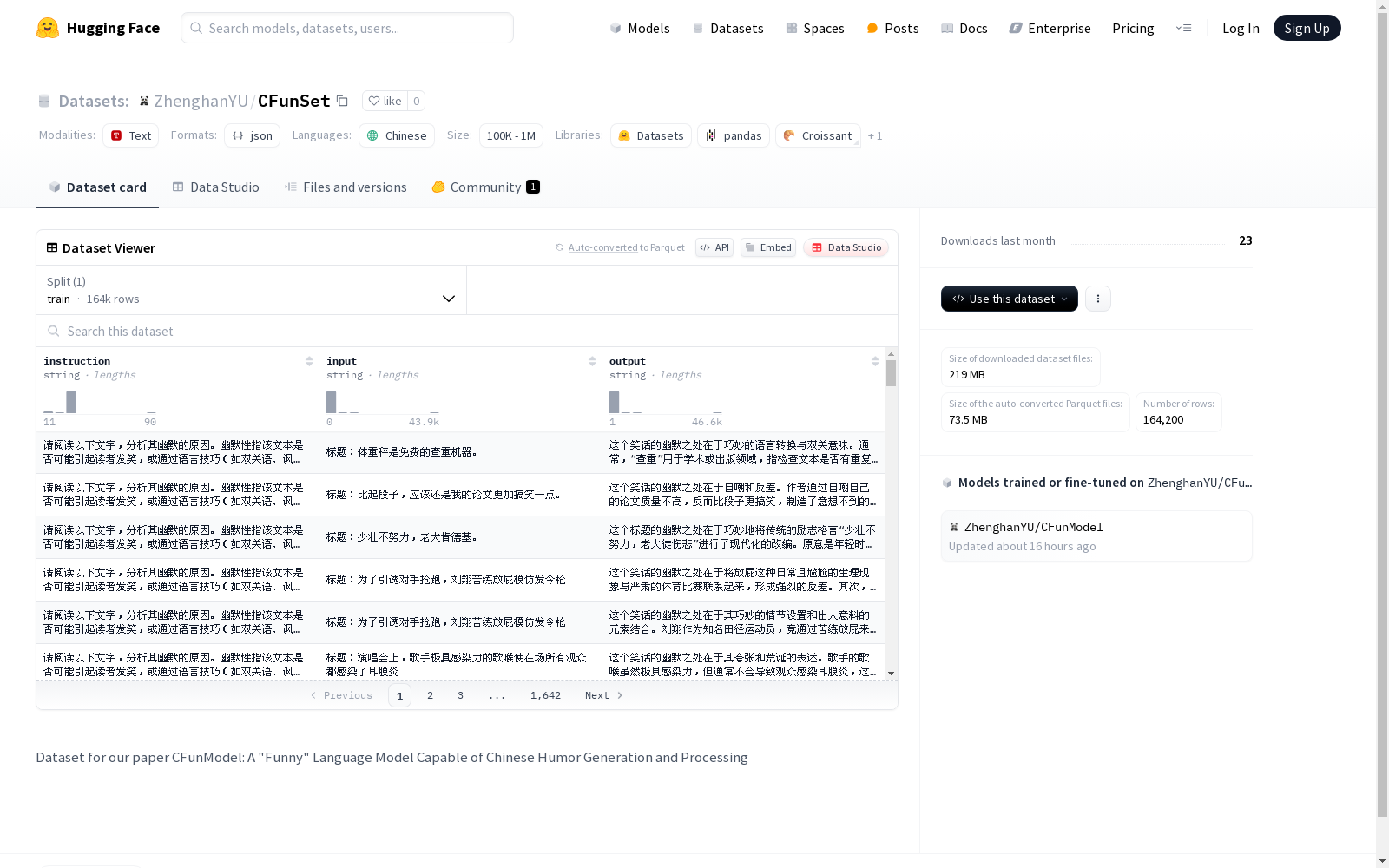
北京大学 本次发布的数据集 Chinese Fun Set (CFunSet), CFunSet是一个全面的中国幽默相关数据集,由北京大学万小军研究团队创建,汇集了现有的中文幽默数据集,并从中国在线论坛贴吧-笑话吧收集了超过2万条笑话,组成的语料库包含超过16万条目。该数据集旨在训练语言模型以处理各种幽默相关任务,如对口相声回应选择、幽默识别、笑话生成等。
Dataset card 内容:
Files and versions 内容:
关于 北京大学 , 北京大学是中国著名的高等教育机构,主要负责培养高等学历人才,致力于促进科技文化的发展。学校提供多层次的学历教育,包括医学、教育学、哲学、经济学、法学、文学、历史学、理学、工学、管理学等各类学科的专科、本科、硕士和博士研究生学历教育,同时还进行博士后培养。在数据资源方面,北京大学拥有丰富多样的数据集,这些数据集涵盖了各个学科的广泛领域,虽然具体数据集特点各异,但都体现了北大学术研究的深度和广度。通过这些数据集,可以一窥北大在科研和教育方面的实力与成果。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)