

牛津大学 本次发布的数据集 HypoGen, HypoGen数据集是由牛津大学等机构的研究人员创建的,包含了从顶级计算机科学会议论文中提取的约5500个结构化问题-假设对。该数据集采用Bit-Flip-Spark模式,其中Bit是传统假设,Flip是创新方法,Spark是关键洞察的简短总结。数据集还包含了一个详细的推理链组件,展示了从传统观点到创新想法的思维过程。该数据集旨在为科学假设生成任务提供支持,解决科学研究中假设生成的问题。
Dataset card 内容:
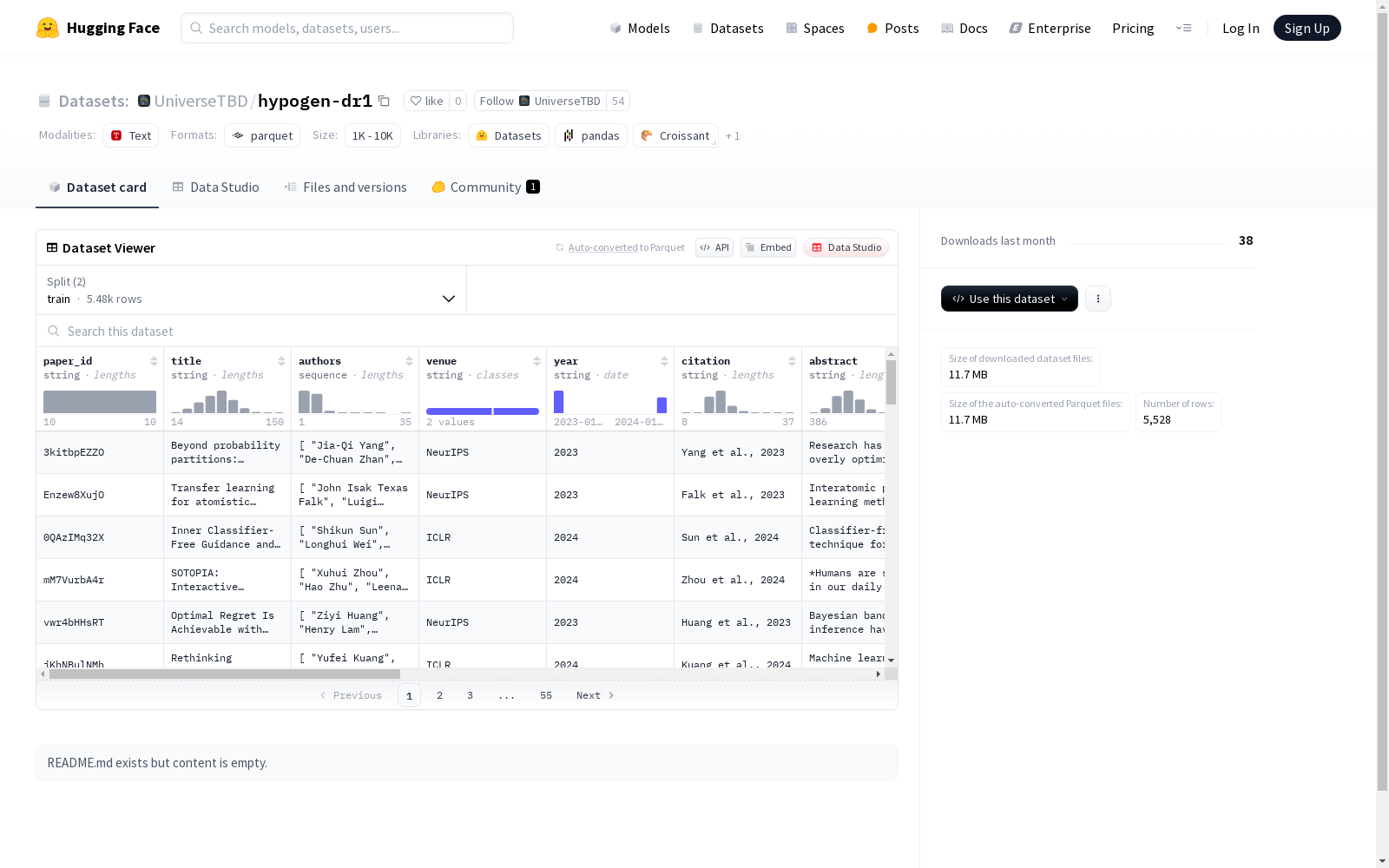
Files and versions 内容:
关于 牛津大学 , 牛津大学是一所位于英国牛津的世界著名研究型大学,以其卓越的学术成就和悠久的历史而闻名。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)