

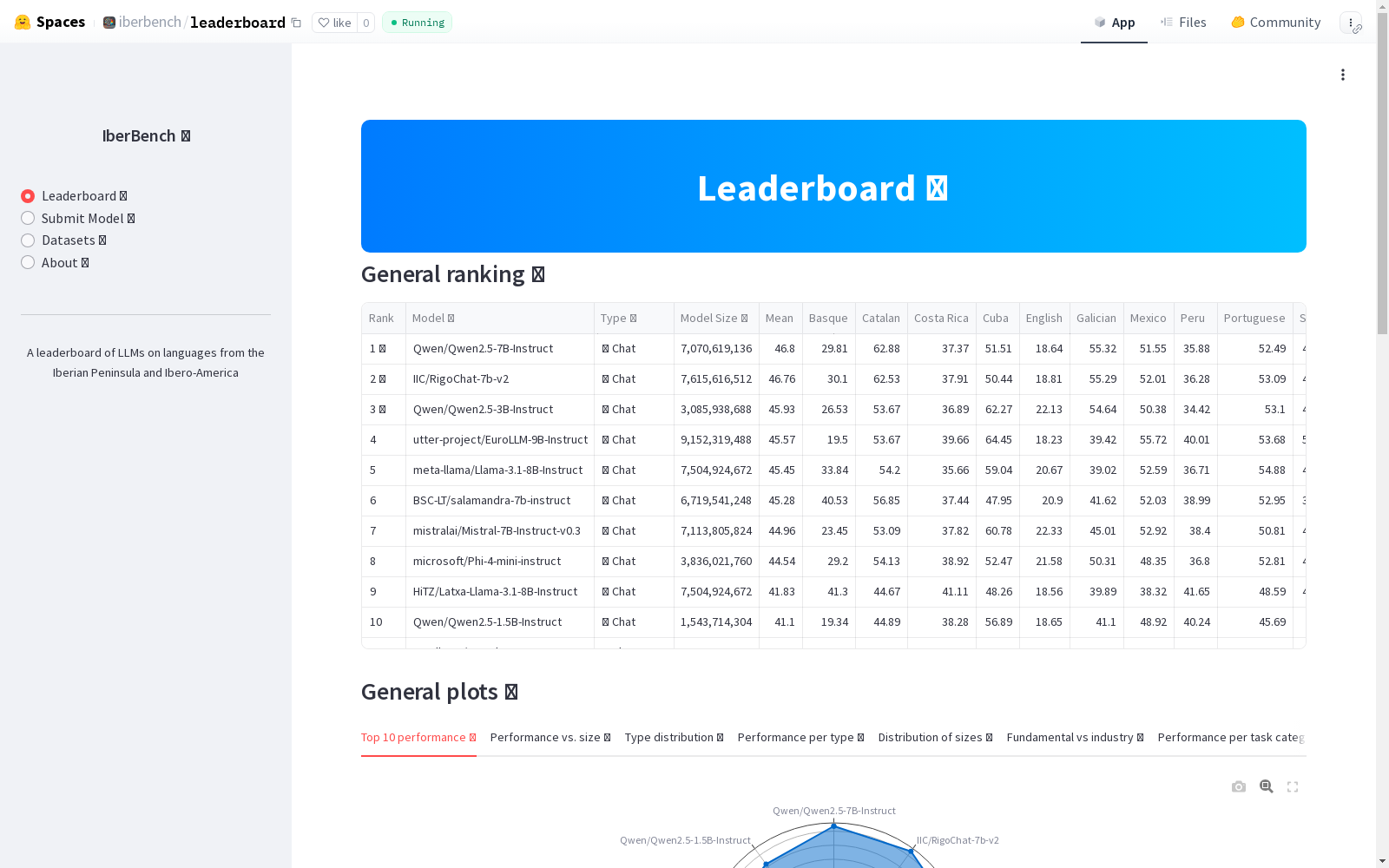
Symanto Research 本次发布的数据集 IberBench, IberBench是一个全面且可扩展的基准测试,旨在评估大型语言模型在伊比利亚半岛和伊比美洲语言的基本和行业相关自然语言处理任务上的性能。该数据集由101个数据集组成,涵盖22个任务类别,如情感和情绪分析、毒性检测和摘要等。IberBench解决了现有评估实践中的关键局限性,如缺乏语言多样性和静态评估设置,通过允许持续更新和社区驱动的模型和数据集提交,由专家委员会进行审核。
Dataset card 内容:
Files and versions 内容:
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)