

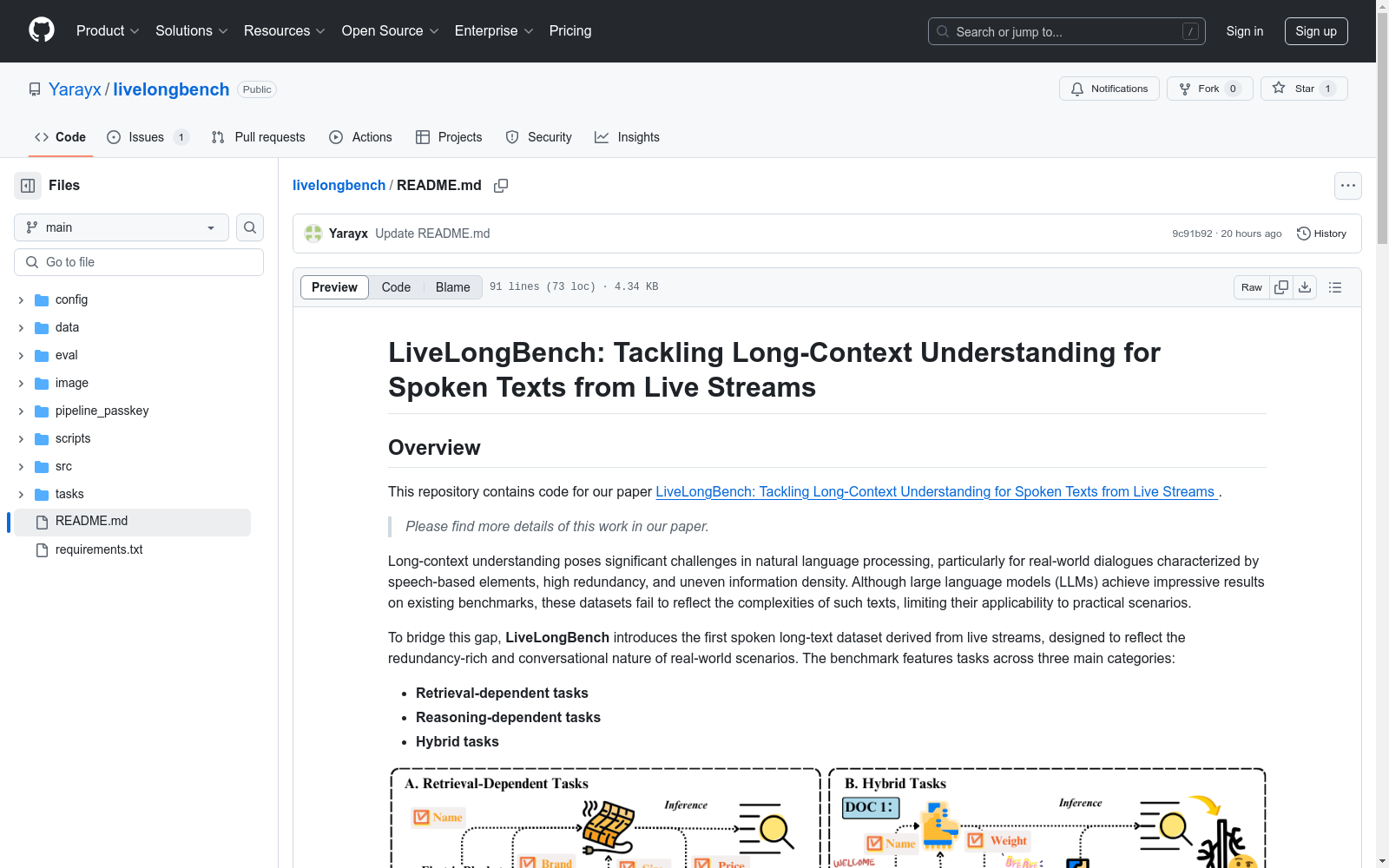
北京国际商务与经济大学 本次发布的数据集 LiveLongBench, LiveLongBench是一个由直播流语音文本构成的第一个双语基准数据集,旨在评估长文本理解和推理能力。该数据集包含约97K个序列,涵盖中文和英文。数据集收集自抖音电商平台直播流,涵盖了11个主要产品类别和32个子类别,具有丰富的语言特征和高度冗余性。该数据集为开发针对口语长文本理解的压缩方法提供了宝贵的测试平台。
README 内容:
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)