

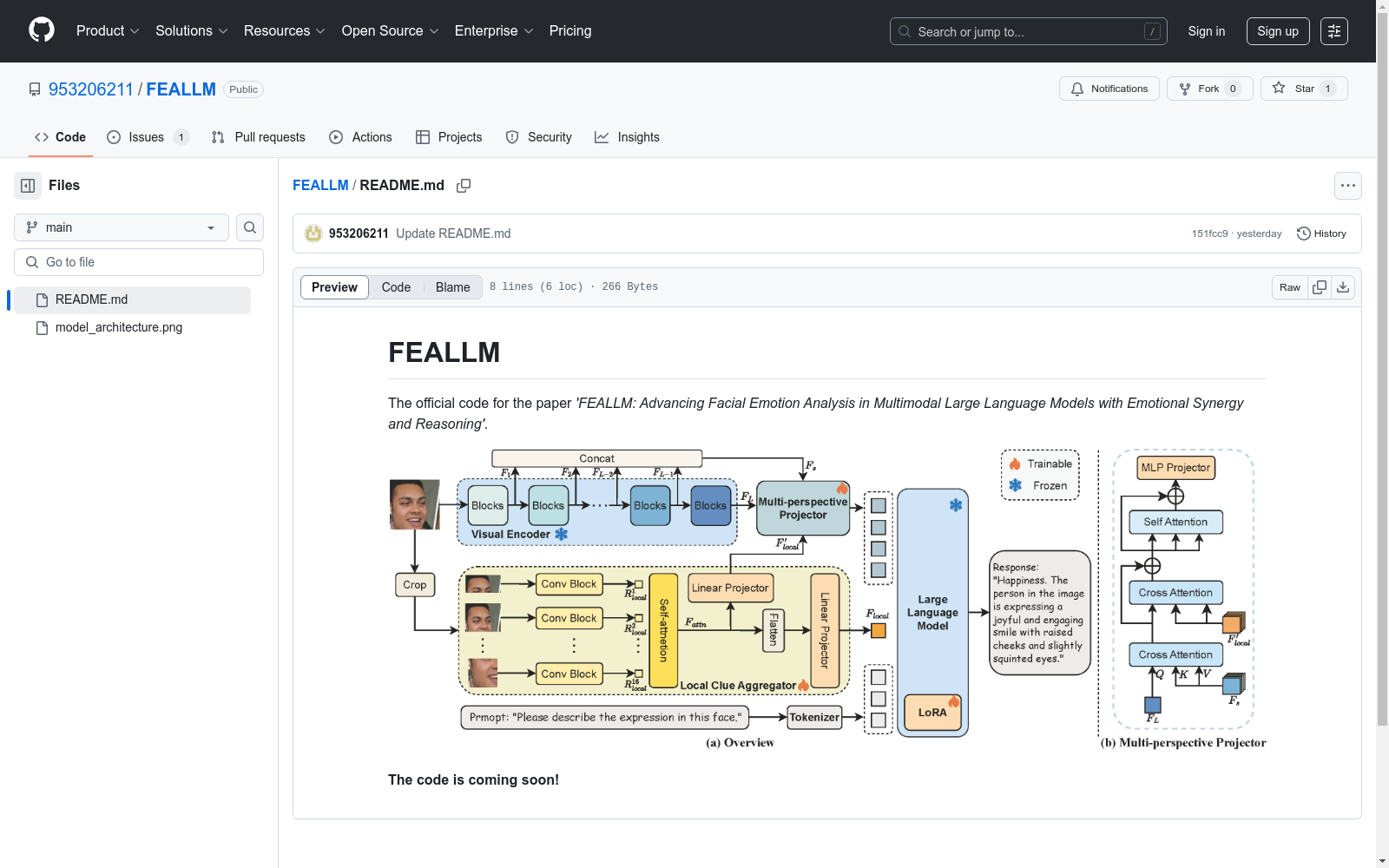
天津大学 本次发布的数据集 FEA Instruction Dataset, FEA Instruction Dataset是一个新型的面部情绪分析指令数据集,旨在通过提供准确且对齐的面部情绪(FE)和面部动作单元(AU)描述以及它们之间的因果推理关系,来提高多模态大型语言模型在面部情绪分析任务中的表现。该数据集基于Aff-Wild2数据集构建,包含16,227张面部图像,其中14,892张用于训练,1,335张用于评估。数据集包含了三种类型的指令:情绪摘要、面部动作描述和情绪推理描述,以便模型能够更深入地理解和感知面部情绪。FEABench是一个新的基准测试,旨在同时评估模型在FER和AUD任务中的表现,以促进模型在两个任务上的协同发展。FEALLM是一个专门为FEA设计的多模态大型语言模型架构,它通过提取面部图像的局部特征并与视觉编码器的低级特征相结合,来增强对局部面部细节的关注,从而提高模型在FEA任务中的表现。
README 内容:
关于 天津大学 , 天津大学是中国历史最悠久的大学之一,位于天津市,是教育部直属的全国重点大学,也是国家‘211工程’和‘985工程’的首批重点建设高校之一。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)