

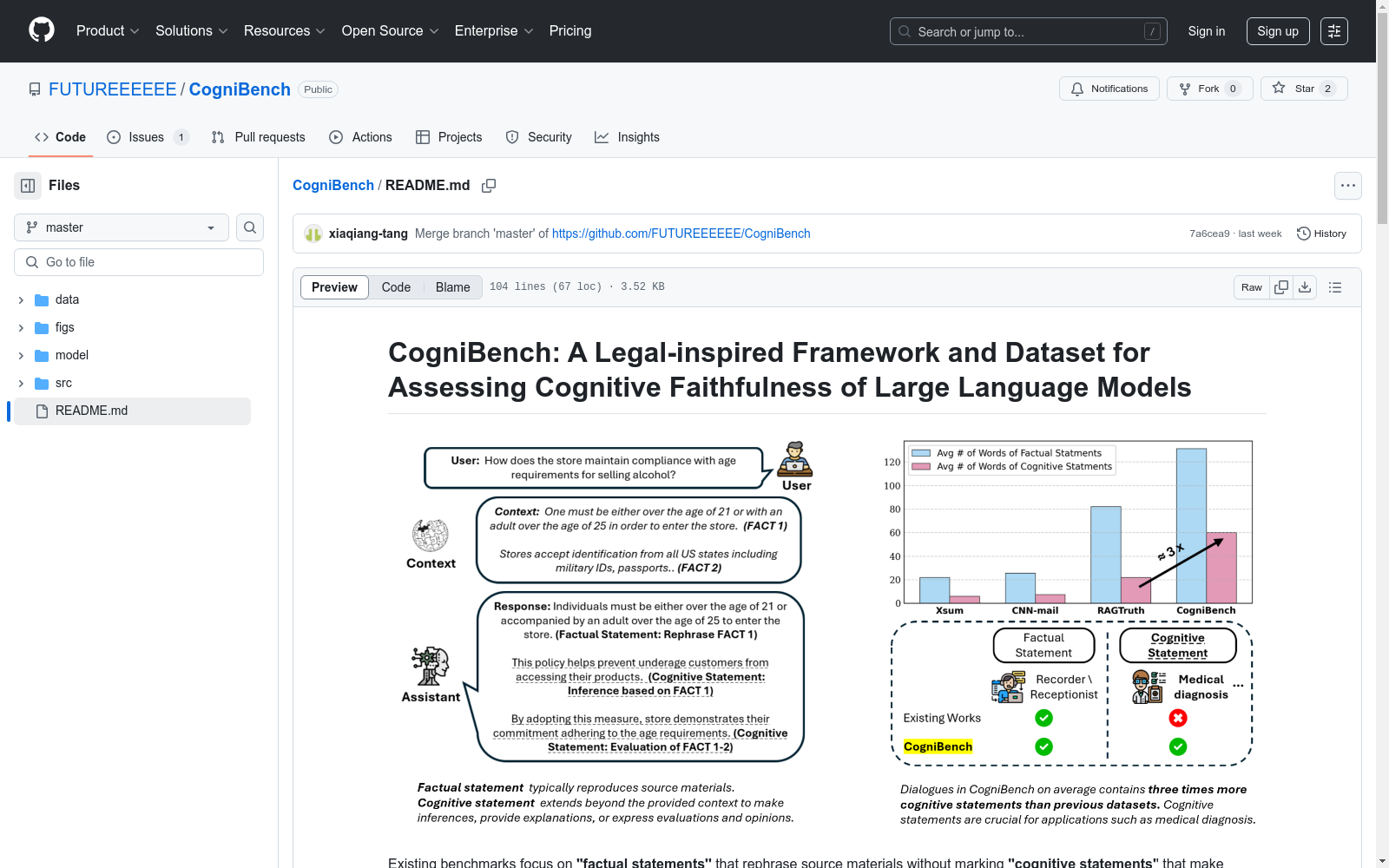
香港科技大学(广州) 本次发布的数据集 CogniBench, CogniBench是一个知识驱动的对话数据集和评估框架,用于评估大型语言模型(LLM)的认知忠实度。该数据集通过严格的人工标注,提供了句子级别的标注,并采用了一种受法律启发的评估协议,以减少主观性。为了满足不同应用领域的需求,CogniBench定义了三个越来越严格的忠实度标准:合理(合理的但不可验证的推测)、有根据的(有上下文支持的评估)和结论性的(无可争议的结论)。这些标准满足了从创意故事讲述到高风险的医疗诊断等不同LLM应用的需求。CogniBench-L是一个大规模的扩展数据集,包含超过24k个对话和句子级别的幻觉标注,支持专门幻觉检测器的训练,并使系统化的基准测试成为可能。
README 内容:
关于 香港科技大学(广州) , 香港科技大学(广州)是香港科技大学在大湾区设立的一个分校区,致力于推动科技创新和人才培养,开展多领域的研究与合作。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)