

英伟达公司 本次发布的数据集 HiFiTTS-2, HiFiTTS-2是一个大规模的语音数据集,用于高带宽语音合成。该数据集源于LibriVox有声读物,包含约36.7k小时的英语语音用于22.05 kHz的训练,以及31.7k小时用于44.1 kHz的训练。数据集还包括详细的语句和有声读物元数据,以便研究人员根据不同的用例对数据集进行质量筛选。实验结果表明,我们的数据管道和生成的数据集可以促进高质量、零样本文本到语音(TTS)模型在高带宽下的训练。该数据集适用于语音合成和语音克隆等应用,并为研究高带宽和混合带宽建模提供了新的数据资源。
Dataset card 内容:
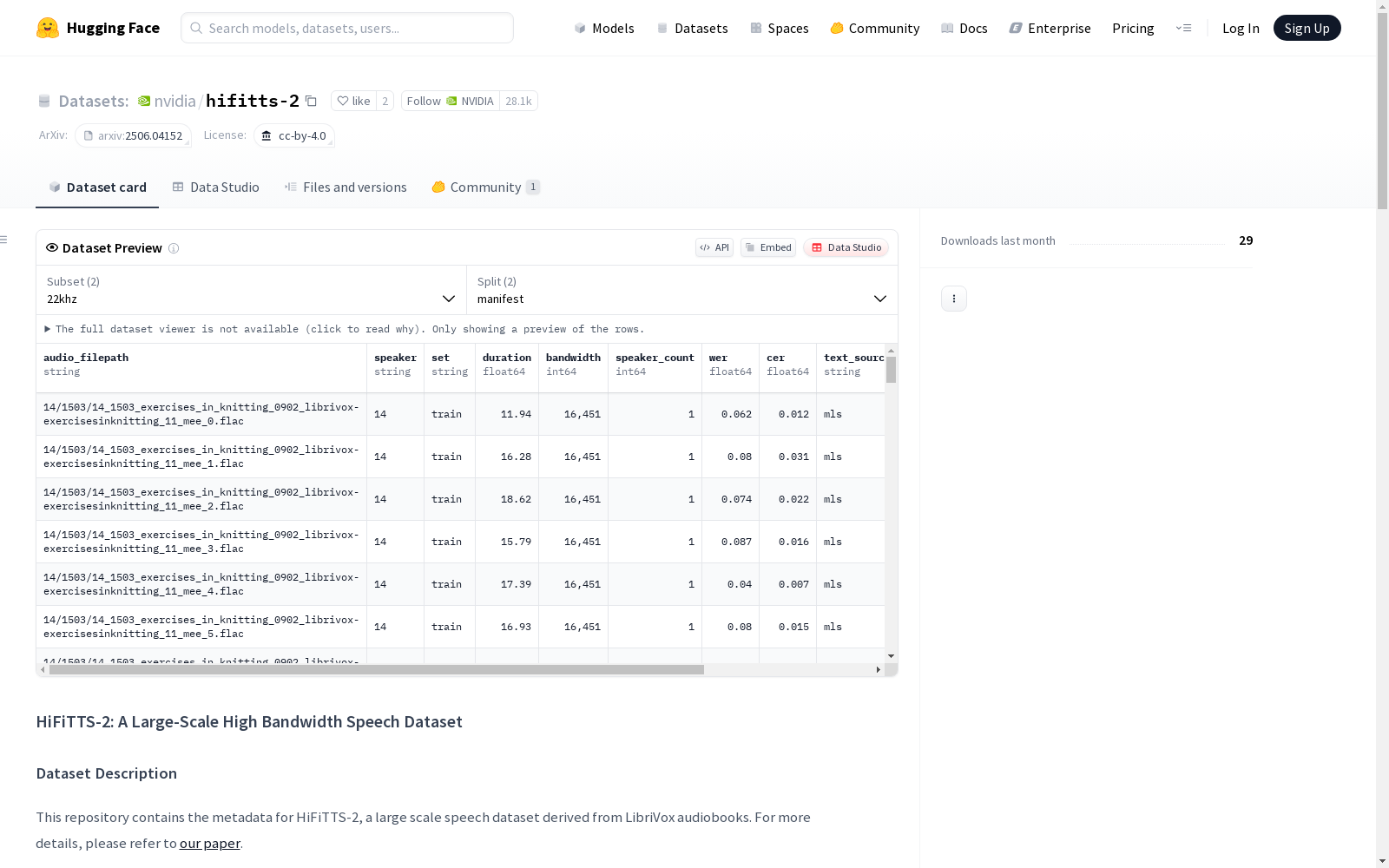
Files and versions 内容:
关于 英伟达公司 , 英伟达公司(NVIDIA)是一家以设计图形处理单元(GPU)为主的科技公司,同时也是高性能计算和人工智能领域的领先企业。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)