

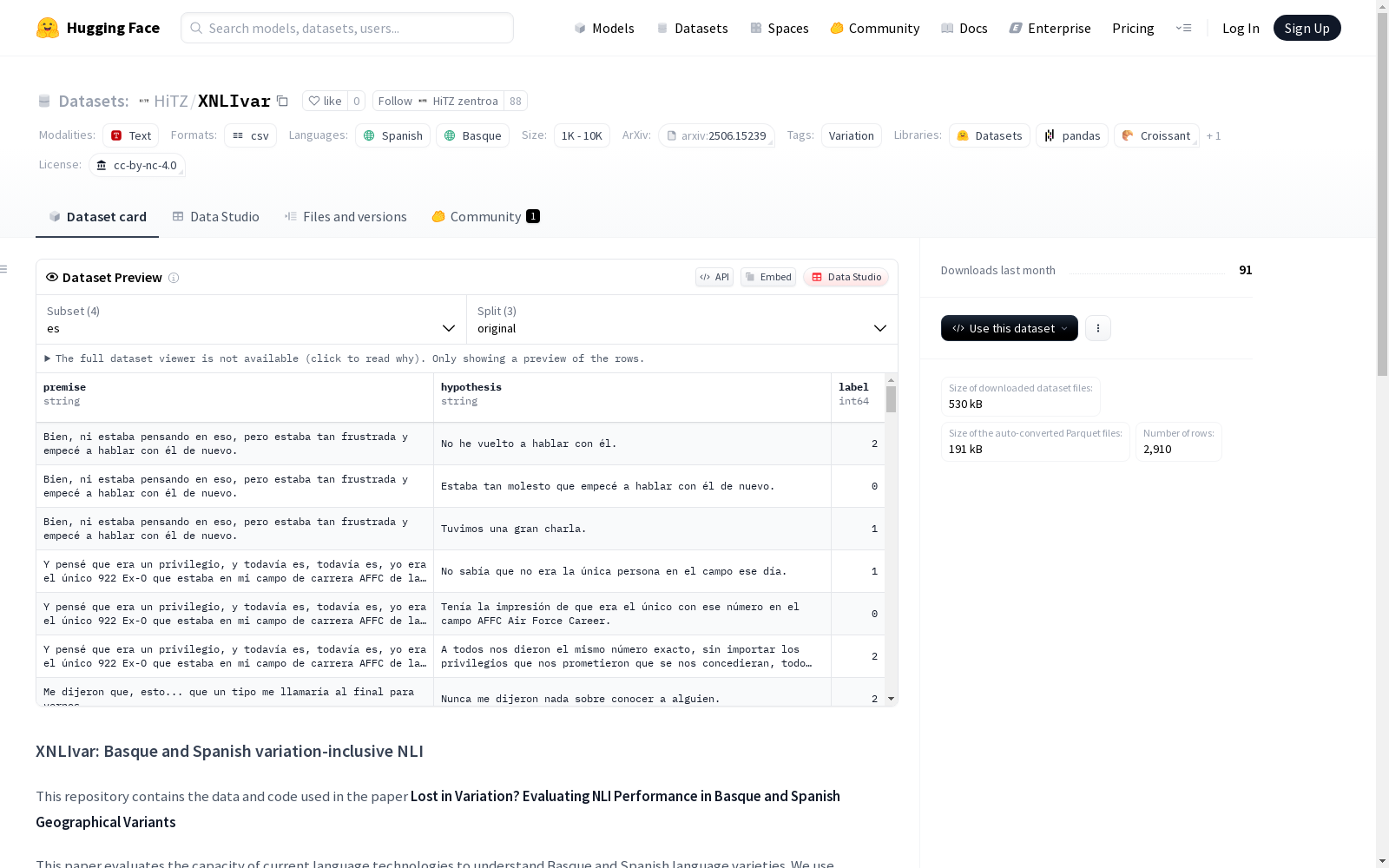
University of the Basque Country UPV/EHU 本次发布的数据集 XNLIvar, XNLIvar数据集是首个公开的手工整理的NLI数据集,用于评估自然语言处理技术对巴斯克语和西班牙语地区语言变体的理解能力。该数据集由HiTZ中心与巴塞罗那大学合作开发,包含了巴斯克语和西班牙语的多种地区语言变体,旨在帮助NLP系统更好地处理不同地区的语言变体。数据集由12位巴斯克语母语者和6位西班牙语母语者参与创建,涵盖了巴斯克语和西班牙语的多个地区变体,包括西部、中部和纳瓦拉地区。数据集共包含1550条数据,其中巴斯克语变体数据894条,西班牙语变体数据666条。该数据集可用于训练和评估自然语言理解模型,以解决跨地区语言变体带来的挑战。
Dataset card 内容:
Files and versions 内容:
关于 University of the Basque Country UPV/EHU , -
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)