

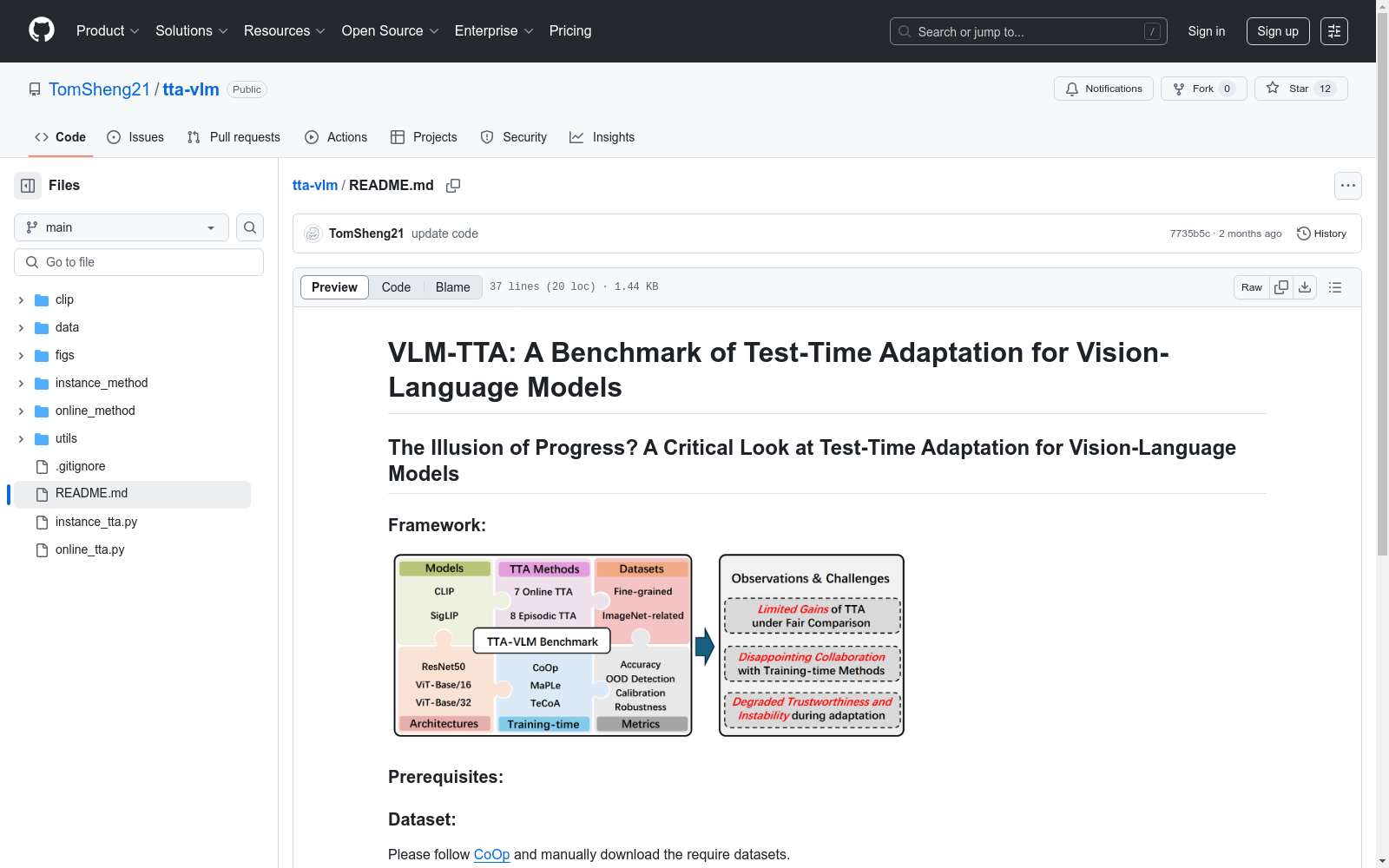
中国科学院自动化研究所 本次发布的数据集 TTA-VLM, TTA-VLM是一个用于评估测试时适应方法(TTA)对视觉语言模型(VLM)性能的综合基准。该基准在统一的框架内实现了8种情景式TTA和7种在线TTA方法,并在15个广泛使用的数据集上进行了评估。与之前只关注CLIP的研究不同,TTA-VLM将评估扩展到使用Sigmoid损失的SigLIP模型,并包括训练时间调整方法,如CoOp、MaPLe和TeCoA,以评估TTA方法的通用性。除了分类精度外,TTA-VLM还采用了多种评估指标,包括鲁棒性、校准、分布外检测和稳定性,从而对TTA方法进行更全面的评估。
README 内容:
关于 中国科学院自动化研究所 , 中国科学院自动化研究所成立于1956年,是中国自动化领域的领先研究机构,主要致力于自动化技术的基础研究和应用研究。模式识别国家重点实验室是其下属的国家级科研平台,专注于模式识别、智能信息处理等领域的研究。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)