

南加州大学 本次发布的数据集 Hyperphantasia, Hyperphantasia是一个合成基准,旨在评估多模态大型语言模型(MLLMs)的内心可视化能力。该数据集由四类精心设计的谜题组成,每个谜题都有三个难度级别,总共包含1200个样本。这些谜题旨在测试模型在推理、预测和抽象等任务中构建和操作内部视觉表示的能力。数据集已公开,可用于评估当前MLLMs在内心可视化能力方面的表现,并探索强化学习在提高视觉模拟能力方面的潜力。
Dataset card 内容:
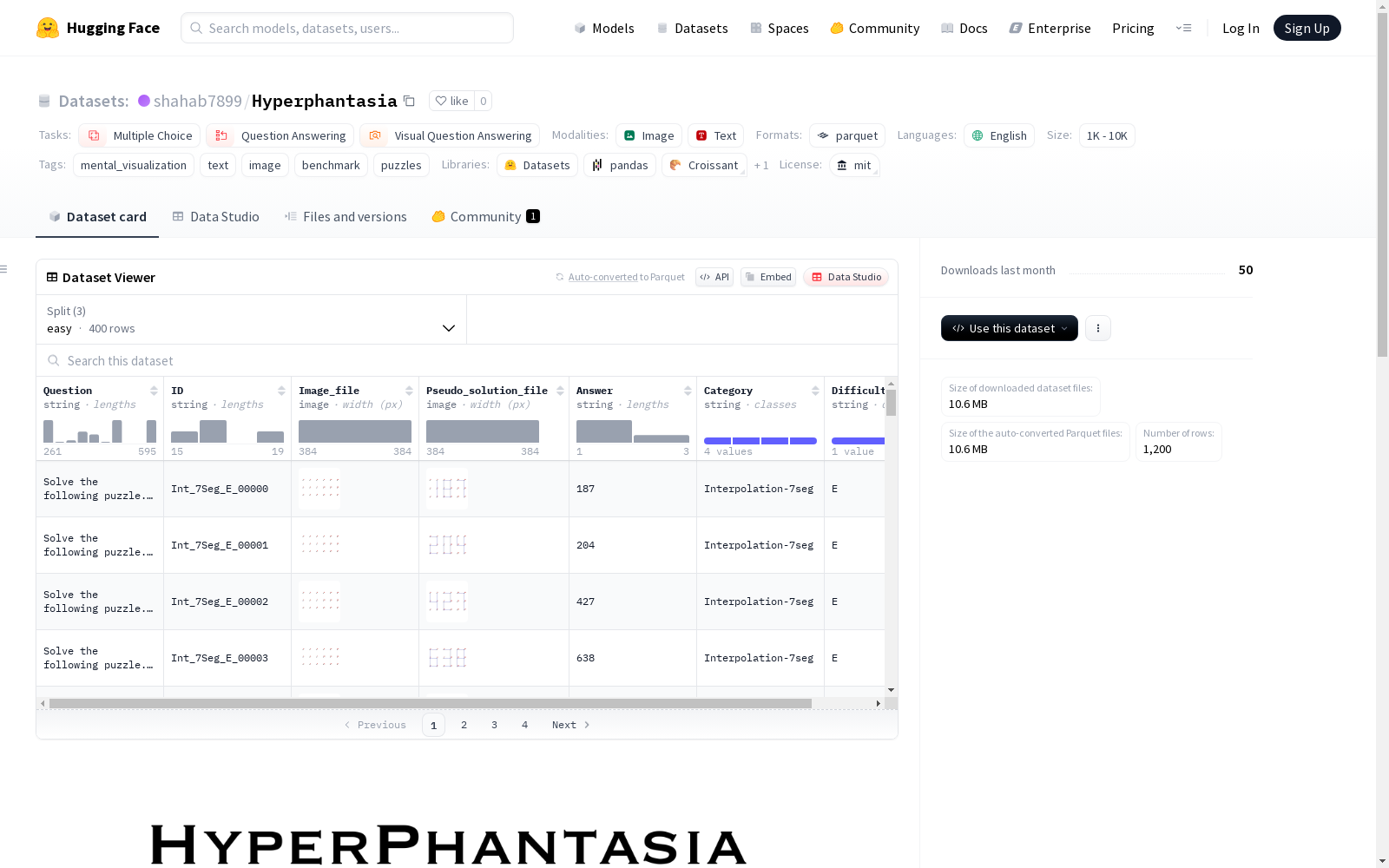
Files and versions 内容:
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)