

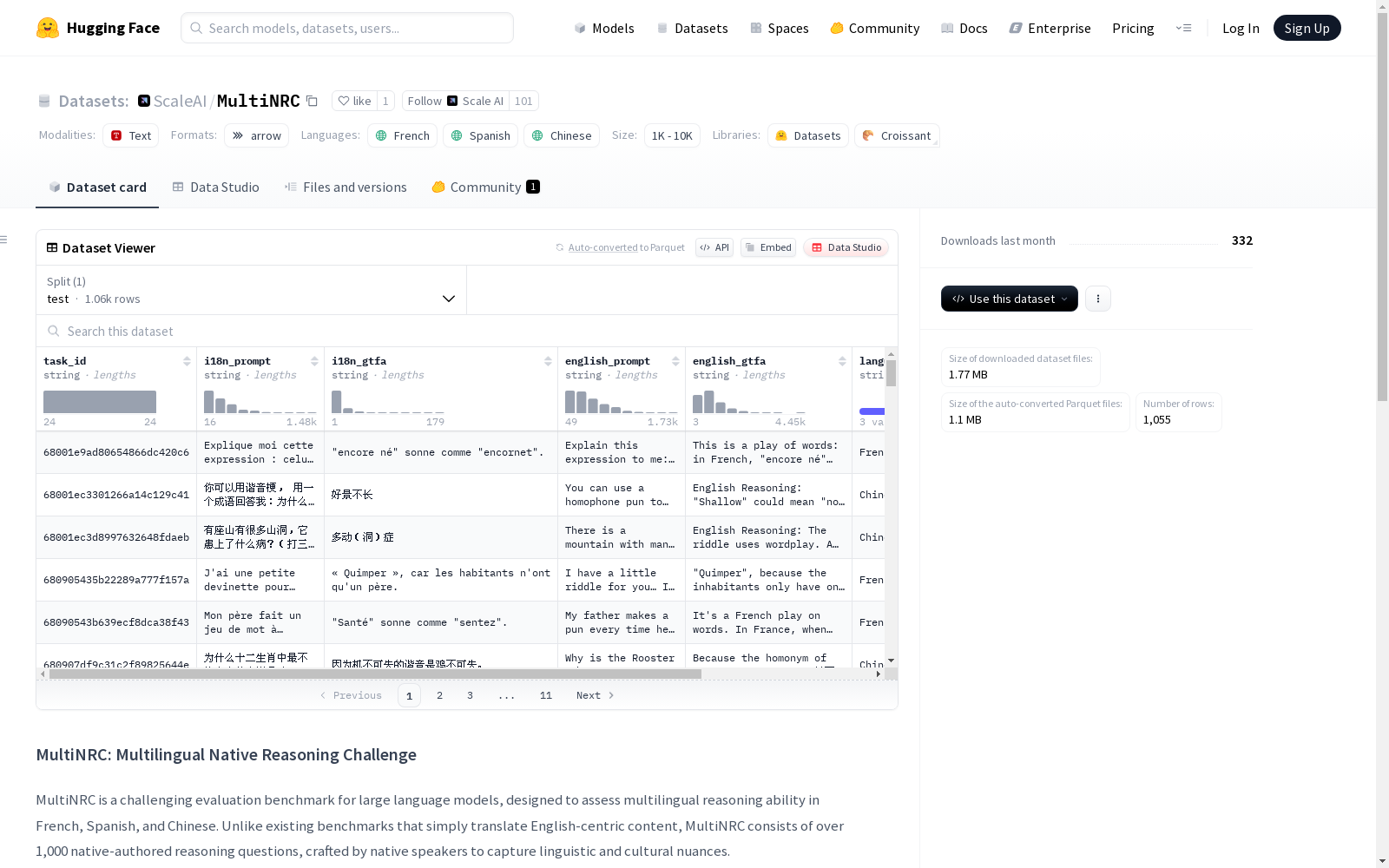
Scale AI 本次发布的数据集 Multilingual Native Reasoning Challenge (MultiNRC), MultiNRC是一个包含超过1000个由法语、西班牙语和中文母语者编写的本族语言和文化背景下的推理问题的评估基准。数据集涵盖了语言特定的语言推理、文字游戏和谜语、文化/传统推理以及与文化相关的数学推理四个核心推理类别。数据集的创建过程包括招募母语者创作具有挑战性的推理问题,并提供客观和简短的最终答案,以方便自动评估。MultiNRC旨在解决当前大型语言模型在多语言推理能力方面的不足,并促进多语言和具有文化背景的评估研究。
查看Multilingual Native Reasoning Challenge (MultiNRC)
Dataset card 内容:
Files and versions 内容:
关于 Scale AI , Scale AI 是一家总部位于美国旧金山的人工智能公司,专注于提供高质量的数据注释服务,以帮助机器学习模型更好地训练和提升性能。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)