

班丹理工学院 本次发布的数据集 INDOPREF, INDOPREF是一个高质量的、完全由人类编写的多领域印尼语偏好数据集,旨在评估大型语言模型(LLM)生成文本的自然性和质量。数据集包含522个由流利的印尼语母语者编写的提示,以及通过明确的成对人类偏好判断进行的注释。数据集涵盖了安全、逻辑、摘要、翻译和创意写作等多个领域,旨在反映不同的现实世界用例并支持不同任务类型之间的鲁棒模型对齐。通过注重母语诱导和注释,INDOPREF填补了代表性不足的语言偏好数据的空白。
Dataset card 内容:
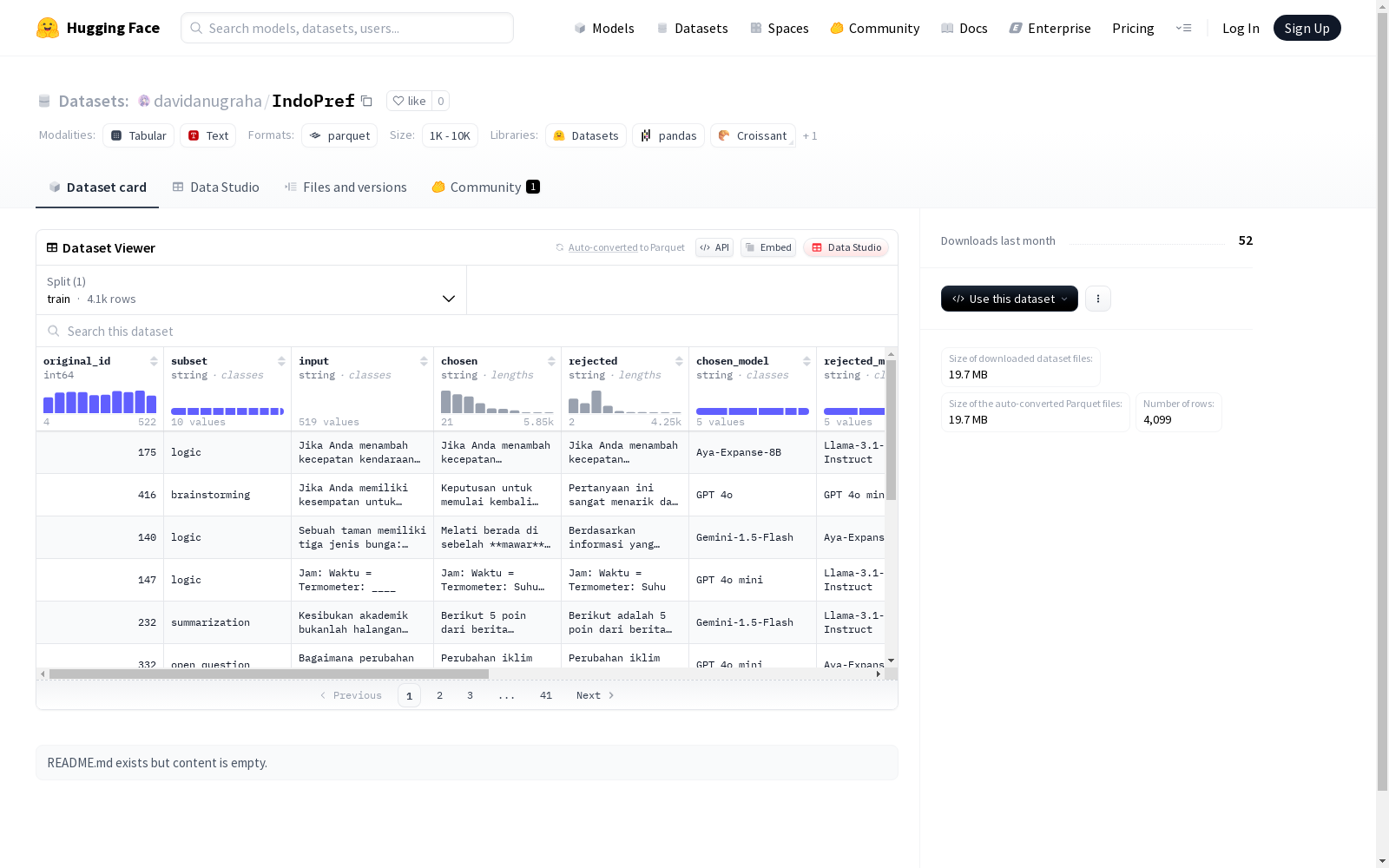
Files and versions 内容:
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)