

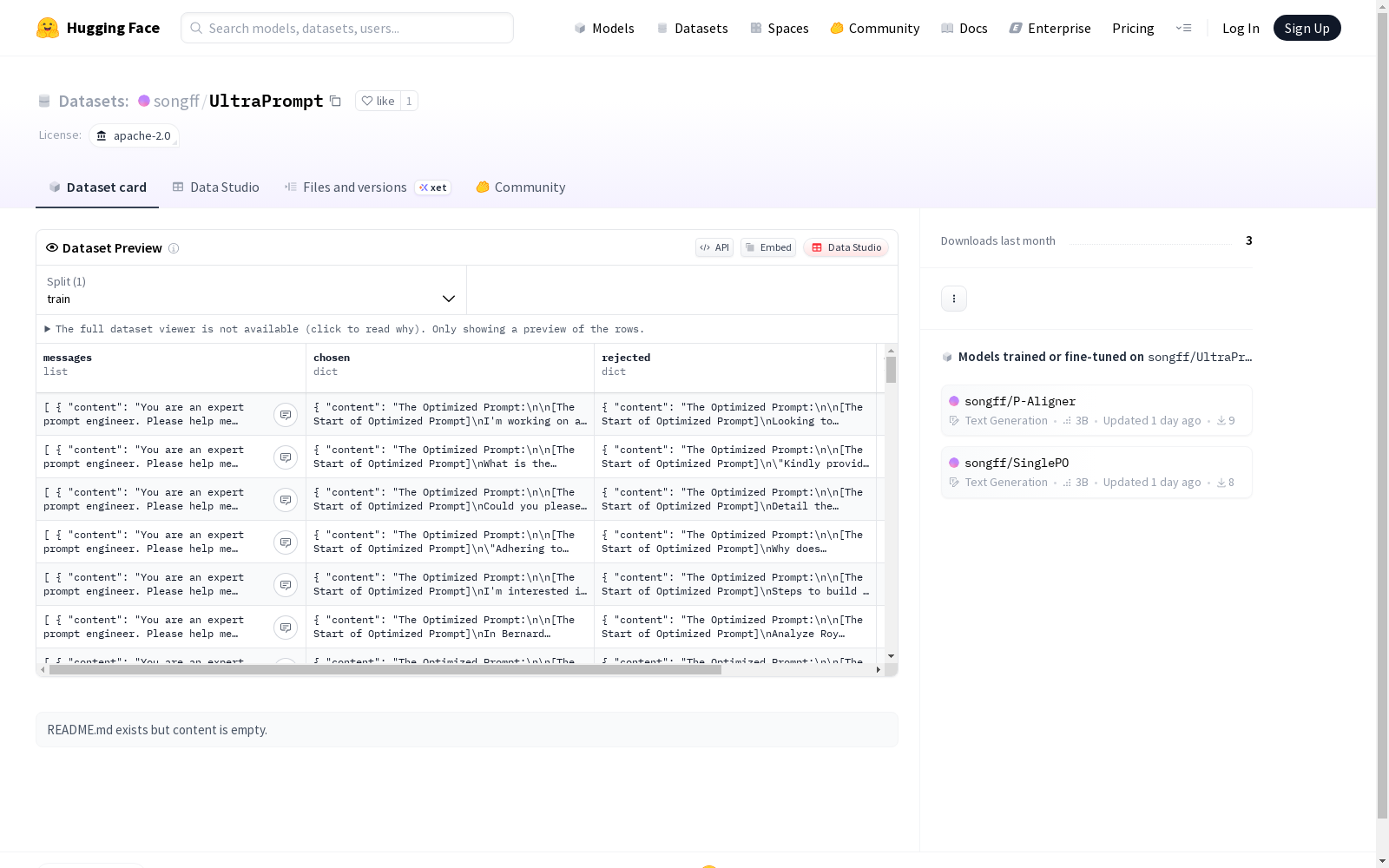
北京大学 本次发布的数据集 UltraPrompt, UltraPrompt是一个通过原则指导的蒙特卡洛树搜索流程合成的数据集,用于训练P-Aligner模块。该模块旨在优化用户输入,使其更符合人类偏好,从而提高大型语言模型(LLMs)的输出质量。UltraPrompt包含10000条种子指令,这些指令来自多个领域,如UltraFeedback、HH-RLHF、Glaive-code-assistant和MathInstruct,以确保数据集的多样性和覆盖范围。UltraPrompt的创建过程涉及使用蒙特卡洛树搜索进行迭代自我编辑,以生成符合人类偏好的高质量指令。P-Aligner通过DPO算法训练,能够在LLM推理之前对指令进行优化,从而显著提高LLM的性能,同时显著降低时间开销。
Dataset card 内容:
Files and versions 内容:
关于 北京大学 , 北京大学是中国著名的高等学府,成立于1898年,位于中国首都北京市。作为中国的顶尖大学之一,北京大学在多个学科领域都有深厚的研究实力和学术影响力。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)