

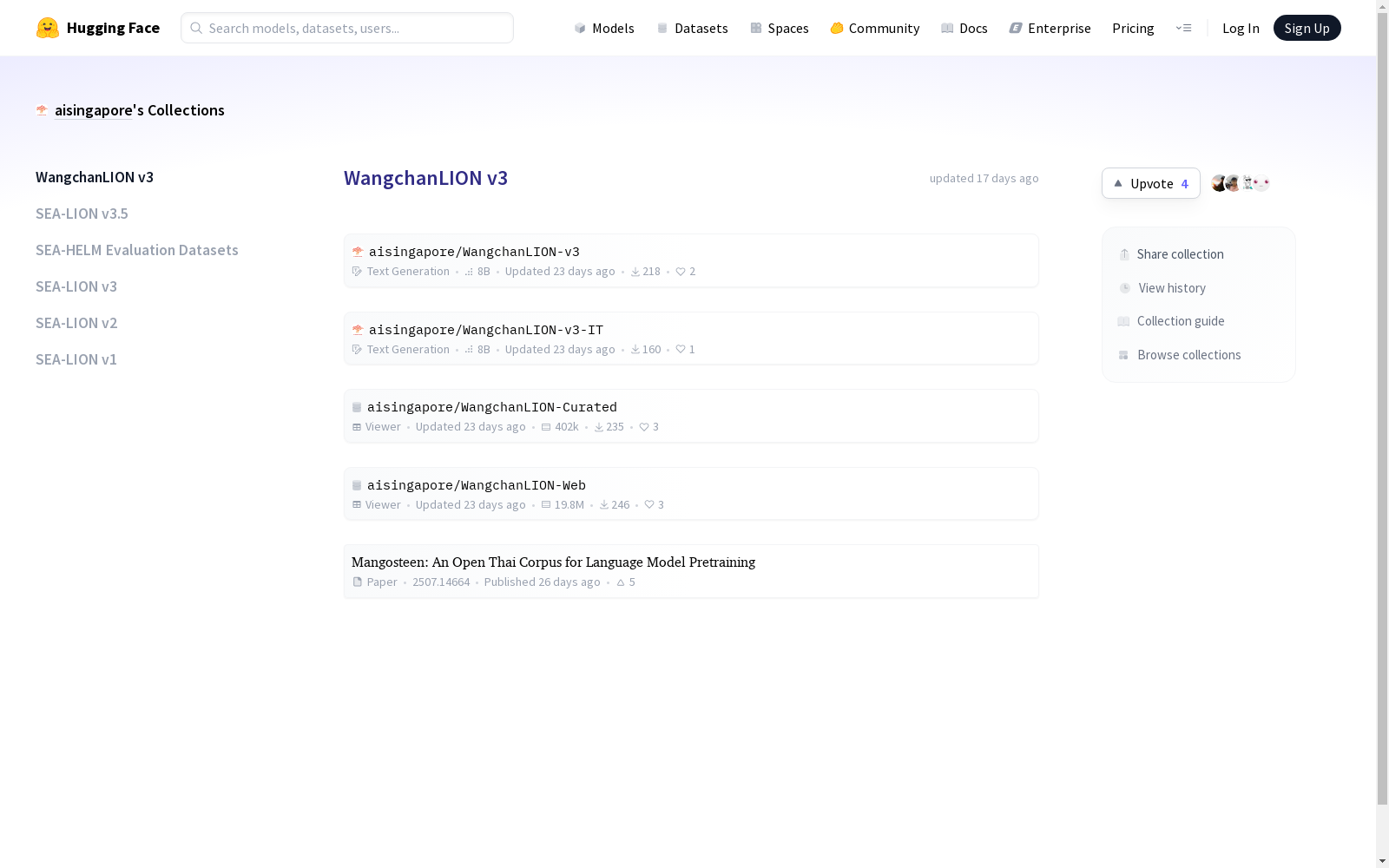
Vidyasirimedhi Institute of Science and Technology 本次发布的数据集 Mangosteen, Mangosteen是一个泰语预训练语料库,包含470亿个token,旨在提高泰语语言模型的质量。该数据集由泰国定制化的Dolma流程构建,包括自定义基于规则的泰语语言ID、修订的C4/Gopher质量过滤器、泰语训练内容过滤器,以及来自维基百科、皇家公报文本、OCR提取书籍和CC许可的YouTube字幕等精选的非网络来源。该数据集通过GPT-2模型进行了系统性的消融研究,结果表明,在泰语基准测试中,Mangosteen数据集相较于未处理的CommonCrawl数据集,文档数量从2亿减少到2500万,同时SEA-HELM NLG得分从3提高到11。此外,一个8B参数的SEA-LION模型在Mangosteen数据集上进行持续预训练后,在泰语基准测试中超越了SEA-LION-v3和Llama-3.1模型约4个百分点。研究团队提供了完整的流程代码、清理清单、语料库快照和所有检查点,为未来的泰语和区域LLM研究提供了完全可复制的基石。
Dataset card 内容:
Files and versions 内容:
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)