

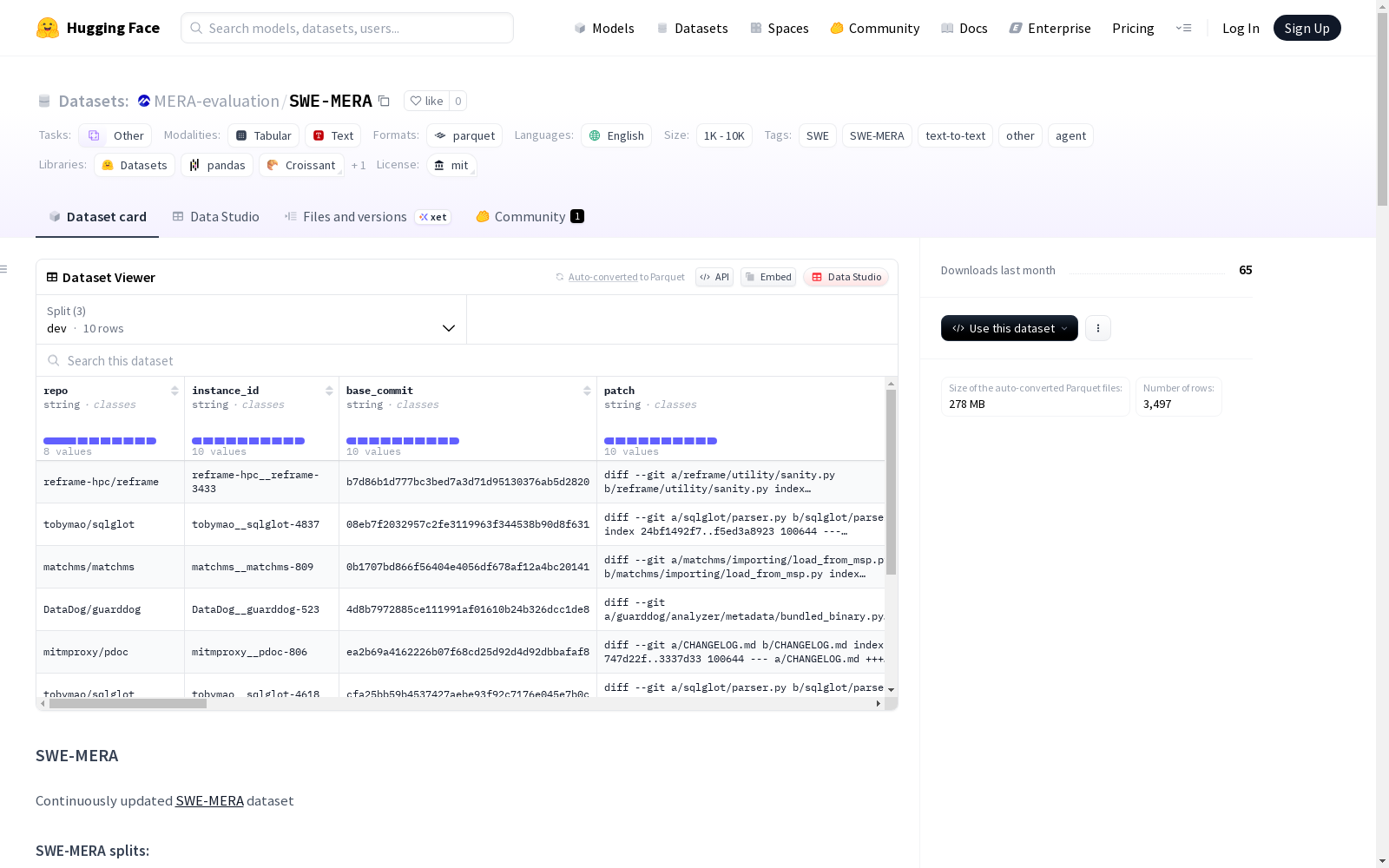
SberAI 本次发布的数据集 SWE-MERA, SWE-MERA是一个动态更新的基准测试数据集,旨在评估大型语言模型在软件工程任务上的性能。它通过自动化收集GitHub上的真实世界问题和严格的验证流程来确保数据质量。数据集目前包含大约300个样本,并有望扩展到10,000个任务。SWE-MERA的设计旨在解决现有软件工程基准测试数据集的局限性,如数据泄露和基准测试饱和问题。它通过定期更新数据集,确保任务与软件开发的最新挑战保持相关性,并为模型提供公平的评价环境。
Dataset card 内容:
Files and versions 内容:
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)