

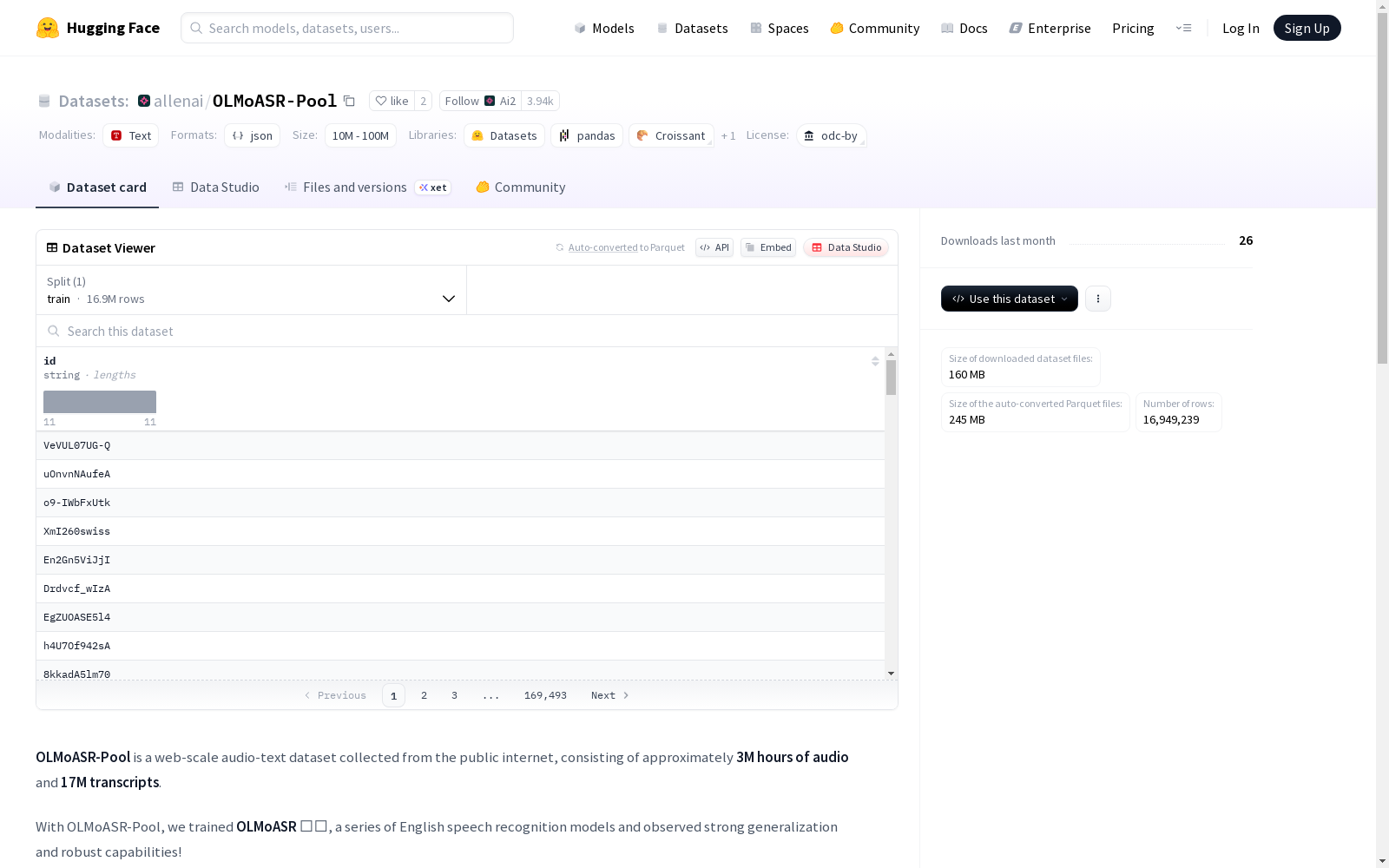
艾伦人工智能研究所 本次发布的数据集 OLMOASR-POOL, OLMOASR-MIX, OLMOASR-POOL是一个包含300万小时英语音频和1700万转录文本的大规模数据集。通过对音频文本进行语言对齐和文本启发式过滤,我们创建了一个包含100万小时高质量音频转录对的新数据集,命名为OLMOASR-MIX。这个数据集被用于训练OLMOASR系列模型,其性能与OpenAI的Whisper模型相当。我们公开了OLMOASR-POOL和OLMOASR-MIX中音频文本对的ID,以及相关的训练、过滤和评估代码,以促进对鲁棒语音识别模型的研究。
Dataset card 内容:
Files and versions 内容:
关于 艾伦人工智能研究所 , 艾伦人工智能研究所(Allen Institute for Artificial Intelligence, AI2)是一个总部位于美国西雅图的非营利研究机构,致力于推动人工智能科学的发展和应用。_simple
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)